
MySQL
MySQL 是一个广泛使用的关系型数据库管理系统(DBMS),用于存储和管理电子数据。MySQL使用表格来组织数据,每个表格包含多个记录(行)和字段(列)。这种结构使得数据易于管理和查询。MySQL可以管理多个数据库,每个数据库中会含有多张表。
另外,推荐MySQL的关键字用大写(虽然不区分大小写),但是英语水平不好,小写更容易记住一点,所以接下来一般都用小写。
下面简单安装一下:以ubuntu为例(可以手动下载 MySQL Workbench可视化工具)
sudo apt update
sudo apt install mysql-server
sudo systemctl start mysql
sudo systemctl enable mysql
sudo mysql -p # 以root用户登录mysql,默认没有密码
下面设置root密码:
> ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '密码'; # 下次登录就需要这个密码了
> flush privileges; # 刷新缓存
重新登录:
sudo mysql -uroot -p
创建用户:先登录root
- 创建用户
# username是用户名
# host是登录IP,为'%'表示任意IP,为'localhost'表示本机
# password为密码
CREATE user 'username'@'host' identified by 'password';
- 授权
# *.*是(数据库.表),就是授予哪个数据库和哪个表,*表示所有数据库/表
# % 表示登录的IP
grant all privileges on *.* to 'username'@'%' with grant option;
- 刷新权限
flush privileges;
- 撤销授权
REVOKE ALL PRIVILEGES ON *.* FROM user_name; # 收回权限(不包含赋权权限)
REVOKE GRANT OPTION ON *.* FROM user_name; # 收回赋权权限
flush privileges; # 刷新权限
MySQL的操作
这一部分的内容只在MySQL上面有,不是SQL的内容。
information_schema, mysql, performance_schema和sys是系统的库,不用去管。
创建数据库
创建数据库有下面的方式:
- 登录数据库创建
create database [if not exists] database_name # database_name为数据库名字,不加 if not exists 就不会检测是否存在同名数据库,存在的话创建失败
character set character_set # 数据集,一般是 utf8mb4
collate collation_name; # 校对规则,一般是 utf8mb4_general_ci
- 使用
mysqladmin创建,在shell就行,不用登录
mysqladmin -u your_username -p create your_database \
--default-character-set=utf8mb4 \
--default-collation=utf8mb4_general_ci
在我们创建数据库之后,登录mysql
show databases; # 显示有哪些数据库
use database_name_; # 使用哪个数据库
show tables; # 显示当前数据库有哪些表
use table_name_; # 使用哪张表
直接使用数据库可以:
mysql -u your_username -p -D your_database
删除数据库
- 登录
drop database [if exists] database_name;
- 使用
shell
mysqladmin -u your_username -p drop your_database
数据类型
mysql支持大部分sql的数据类型
1)数值类型
| 类型 | 大小(字节) | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| TINYINT | 1 | (-128, 127) | (0,255) | 大整数值 |
| SMALLINT | 2 | (-32768, 32767) | (0,65535) | 大整数值 |
| MEDIUMINT | 3 | (-8388608,8388607) | (0,16777215) | 大整数值 |
| INT/INTEGER | 4 | (-2147483648,2147483647) | (0,4294967295) | 大整数值 |
| BIGINT | 8 | (-9223372036854775808,9223372036854775807) | (0,18446744073709551615) | 大整数值 |
| FLOAT | 4 Bytes | (-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) | 0,(1.175 494 351 E-38,3.402 823 466 E+38) | 单精度 浮点数值 |
| DOUBLE | 8 Bytes | (-1.797 693 134 862 315 7 E+308,-2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 双精度 浮点数值 |
| DOUBLE(M,D) | 8,(M代表长度,D代表小数位) | 同上,受M,D的约束DOUBLE(5,2)-999.999,+999.999 | 同上,受M,D的约束 | 双精度浮点数值 |
| DECIMAL(M,D) | DECIMAL(M,D) | 依赖于M,D的值,M最大值65 | 小数值 |
2)日期类型
| 类型 | 大小 | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | ‘-838:59:59’/‘838:59:59’ | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | ‘1000-01-01 00:00:00’ 到 ‘9999-12-31 23:59:59’ | YYYY-MM-DD hh:mm:ss | 混合日期和时间值 |
| TIMESTAMP | 4 | ‘1970-01-01 00:00:01’ UTC 到 ‘2038-01-19 03:14:07’ UTC结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07 | YYYY-MM-DD hh:mm:ss | 混合日期和时间值,时间戳 |
3)字符串
| 类型 | 大小 | 用途 |
|---|---|---|
| CHAR | 0-255 bytes | 定长字符串 |
| VARCHAR | 0-65535 bytes | 变长字符串 |
| TINYBLOB | 0-255 bytes | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-255 bytes | 短文本字符串 |
| BLOB | 0-65 535 bytes | 二进制形式的长文本数据 |
| TEXT | 0-65 535 bytes | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215 bytes | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295 bytes | 极大文本数据 |
4) 枚举与集合类型(Enumeration and Set Types)
- ENUM: 枚举类型,用于存储单一值,可以选择一个预定义的集合。
- SET: 集合类型,用于存储多个值,可以选择多个预定义的集合。
5) 空间数据类型(Spatial Data Types)
GEOMETRY, POINT, LINESTRING, POLYGON, MULTIPOINT, MULTILINESTRING, MULTIPOLYGON, GEOMETRYCOLLECTION: 用于存储空间数据(地理信息、几何图形等)。
创建表
create table [if not exists] `table_name` ( # 这里的反引号作用就是防止名字中出现 mysql 不允许的字符,也可以理解成字符串
`col_name1` int unsigned auto_increment # auto_increment 表示自动增加
`col_name2` varchar(100) not NULL, # not null表示不能为null
`col_name3` varchar(30) NULL, # 表示可以为null
`col_name4` boolean default true, # 表示默认为true
`col_name5` date, # 创建日期类型的
...
primary key (`col_namex`) # 设置主键,后面讨论主键和外键
)
engine=InnoDB # 指定引擎使用InnoDB,默认不用管
CHARACTER SET utf8mb4 # 指定数据集,默认和数据库用的一样的数据集
COLLATE utf8mb4_general_ci; # 指定校验,默认和数据库用的一样的
# 其中主键也可以写在列名后面
create table `table_name` (
`col_name1` int unsigned primary key auto_increment # 设置主键
);
删除表
drop table [if exists] table_name_; # 删除表
truncate table table_name_; # 删除表的所有数据,但是表并没有被删除(结构保留了)
更改表结构
# 新增列,将 database_name.table_name_ 的表新增一列,类型为,且非空
alter table database_name.table_name_ add column `col_name` varchar(10) not null;
# 修改列,将 database_name.table_name_ 表的 source_col_name 改成 `dst_col_name` varchar(20) not null
alter table database_name.table_name_ change column `source_col_name` `dst_col_name` varchar(20) not null;
# 删除列,将 database_name.table_name_ 表的 col_name 删除
alter table database_name.table_name_ drop column `col_name`;
关系型数据库
介绍
MySQL的数据库其实是一种关系型数据库,何谓关系,即一对一,一对多,多对一(注,多对多其实是一对多和多对一的组合)。
关系型数据库最基本的存储容器是表,类似于excel软件一样。
想象有三张表,学生表、班级表和班主任表。
学生表对班级表,那就是对多一的关系
班级表对学生表,那就是一对多的关系
班级表与班主任表之间,就是一对一的关系。
上面学的都是MySQL的命令与代码,下面将要学习的是SQL(Structured Query Language),这是一种编程语言,关系型数据库就是使用这种语言进行交互的,最核心的四个功能就是,增删改查。
下图是SQL语言的命令分类
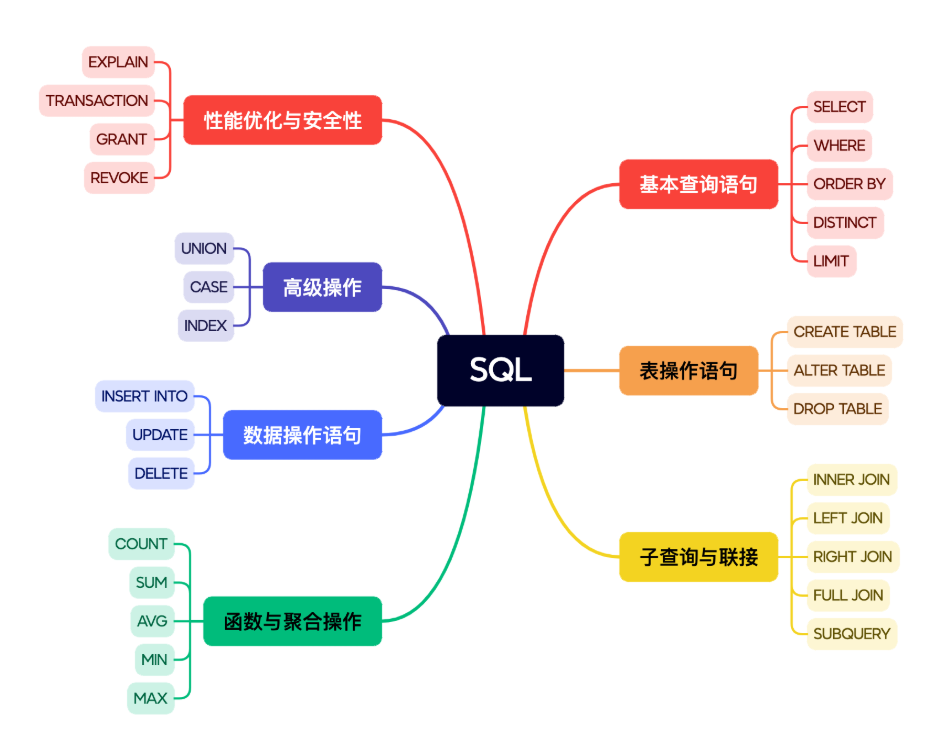
关系键
接下来讲讲主键和外键,一张表如何区分两行数据是否相同?只要两行数据有一列位置上的数据不同,那么两行数据就是不同的。但是那就需要整列整列比较了,往往可以通过指定一列作为对比,这样会比较快速。这一列区分不同数据的,称之为主键。
一般来说,使用自增来作为主键,即id。亦或者是使用UUID算法来作为主键。千万不要使用业务数据,比如年龄、姓名、身份证号等作为主键。
主键还可以有联合主键,就是使用多列来区分,比如两列,那么主键就是约束这两列不能完全重复。
继续以三张表,学生、班级和班主任表作为例子。
已知,在三张表中,均使用自增id作为主键,如何实现学生和班级的对应呢(多对一,多个学生对应一个班级)?那么就可以在学生表中新增一列班级id,还可以使用数据库的外键约束来强化这种对应关系,但是外键约束会导致性能下降,所以在应用程序中手动对应这种外键关系会更好。
如何实现一对一的关系呢?(一个班级对应一个班主任),也可以使用外键来对应。
拆表:有时候一张大表,比如学生表,存储了几千个学生,会包括许多数据,比如:姓名、电话、QQ、微信、年龄、班级、家庭等等,也并不是所有学生都填了每一个信息的,比如有些学生没有微信,有些学生不填家庭住址等等。那么就可以单独提取一个微信表,即生成一张新的表id, 学生id, 微信。也可以把不常用的数据和常用数据分开,这样加快访问速度。
索引,mysql会允许对某一列标记为索引,可以理解成它在插入的时候就排序了,这样查找起来快多了。对于查远远大于增的表,这种方式是很不错的。对于主键是自动建立索引的,因为其是递增的,插入也是非常快的。(索引在后面可以看到详细介绍)
事务
事务就是将一条或者多条SQL语句封装在一起,所有SQL语句被成功执行,那么整个事务成功,有一条SQL语句执行失败,则事务失败,事务失败会回滚所有的SQL语句,可以把一个事务想象成一个原子操作。事务满足ACID性质,即原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。
常见用途,在转账的时候就非常重要等。
begin [或 start transaction]; 开启一个事务
SQL语句1;
SQL语句2;
savepoint <检查点名字>;
SQL语句3;
SQL语句4;
# 如果出错了,可以回滚整个事务或者回滚到某个检查点
rollback; # 回滚整个事务
rollback to savepoint <检查点名字>; # 回滚到某个检查点
commit; # 如果发现没有出错,那么就可以提交了。
# 回滚和提交往往需要在应用程序中自行判断
索引
数据库往往使用B树或者B+树来作为存储结构的,而这两种树都有一个共同点,其键值key是排序的。在这两种数据结构中进行搜索的平均复杂度是O(\log n),因此,可以设置表的某一列或者某几列作为这个key,那么这些列就是索引。当然,索引加速SQL语句的执行主要在于WHERE对索引进行过滤,所以建议把常用的过滤列设置成索引。索引由于增加了一个数据结构(树中节点要保存数据行的地址),所以需要消耗额外的存储空间,是一种典型的以空间换时间的做法。
普通索引
- 创建索引,以下是创建索引的几种方式
create index <索引名字>
on <表名字> (<列名字1> [ASC|DESC], <列名字2> [ASC|DESC], ...) # 可使用多列来作为索引,默认是ASC排序
;
# 上下两种方法都是在已有的表上面增加索引
alter
table <表名字>
add index <索引名字>
(<列名字1> [ASC|DESC], <列名字2> [ASC|DESC], ...)
;
# 下面是在创建表的时候指定索引
create table <表名字> (
<列名字1> <数据类型> [约束],
<列名字2> <数据类型> [约束],
...
index <索引名字> (<列名字1> [ASC|DESC], <列名字2> [ASC|DESC], ...)
);
- 删除索引
drop index <索引名字> on <表名>;
# 或者
alter
table <表名字>
drop index <索引名字>
;
唯一索引
如果索引的值重复的越少,那么查询效率应该是越高的,因此,唯一索引就是这么个约束。唯一索引要求,该列的值必须唯一。
- 创建唯一索引
create unique index <索引名字>
on <表名字> (<列名字1> [ASC|DESC], <列名字2> [ASC|DESC], ...)
;
# 上下两种方法都是在已有的表上面增加唯一索引
alter
table <表名字>
add constraint <索引名字> unique
(<列名字1> [ASC|DESC], <列名字2> [ASC|DESC], ...)
;
# 下面是在创建表的时候指定唯一索引
create table <表名字> (
<列名字1> <数据类型> [约束],
<列名字2> <数据类型> [约束],
...
constraint <索引名字> unique (<列名字1> [ASC|DESC], <列名字2> [ASC|DESC], ...)
);
- 删除唯一索引
drop index <索引名字> on <表名>;
# 或者
alter
table <表名字>
drop constraint <索引名字>
;
查看索引
show index from <表名>;