前言
不知道为什么忽然想快速学一下这门课,所以就快速学一下这门课了。
书籍参考《数值分析》何汉林、梅家斌主编和《实用数值分析》杜迎春主编的两本书,因为我目前就找到了这两本书,图书馆借的,马上就要到期了。
第一章 绪论
第1节 什么是数值分析
数值分析也称计算方法,是数学科学的一个重要分支,它是研究计算机求解数值解的计算方法及其软件实现。
第2节 数值计算的误差
- 第一类是截断误差或方法误差:将数学问题转化为计算问题时产生的误差,比如泰勒近似会引入一个小误差。
- 第二类是舍入误差:在计算中由于保留小数位有限而造成的误差。
设准确值x的近似值为x*,则e(x∗)=x−x∗称为x*的绝对误差,绝对误差一般无法求解精确值,只能得出误差限δ(x∗)。er(x∗)=xx−x∗被称为相对误差。
第二章 直接法解线性方程组
⎩⎪⎪⎪⎨⎪⎪⎪⎧a11x1+a12x2+⋯+a1nxn=a1,n+1a21x1+a22x2+⋯+a2nxn=a2,n+1……an1x1+an2x2+⋯+annxn=an,n+1
第1节 消元法
- Gauss消元法:毫无疑问,在线性代数中肯定学过,如果没有学过线性代数的话,可以先去学线性代数。也就是将矩阵先化成上三角矩阵,然后再自下而上的求解。
- Gauss-Jordan消去法:与高斯消元法类似,不过是先化成对角矩阵,然后再求解。
无论是哪种消元法,其计算的复杂度都是O(n3)级别的。
除此之外,还有主消元法。主消元法是由于直接消元法在计算中可能会导致较大的误差,所以需要用主消元法。主元是指:绝对值最大的元素。
第2节 直接三角分解法
- A=LU分解:L是下三角矩阵,U是上三角矩阵,A需要是非奇异方阵且1至n-1阶的顺序主子式不等于0。
- A=LDU分解:L是下单位三角矩阵,D是对角矩阵,U是上单位三角矩阵。A需要是非奇异方阵,且充要条件是各阶顺序主子式不为0.(单位三角矩阵是指对角线全1)
- A=PLU分解:P是置换矩阵,L是下三角矩阵,U是上三角矩阵。
第3节追赶法
追赶法适用于快速求解三对角矩阵方程,如下图所示:
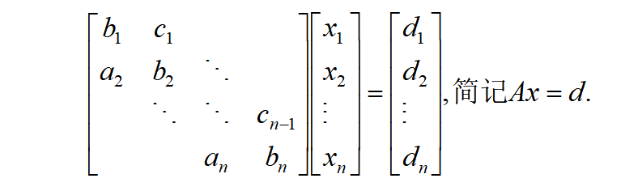
求解步骤:
- 分解成A=LU(并且其中蕴含着A=Ly,y=Ux)
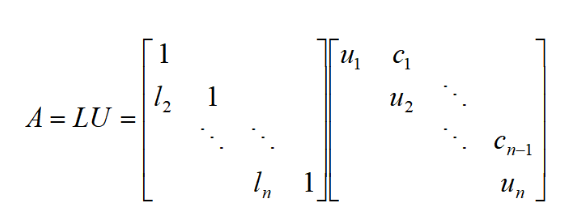
- 给出分解公式:
li=ui−1ai2≤i≤nui={b1,bi−ci−1li,i=11<i≤n
- 解Ly=d:
yi={d1,di−liyi−1,i=11<i≤n
- 解Ux=y:
xi={unyn,uiyi−cixi+1,i=nn>i≥1
第4节 范数
-
向量范数:也就是向量的模,记为∥x∥。在向量空间Rn中最常见的向量范数有以下3种:
- 无穷范数:∥x∥∞=max(∣x1∣,∣x2∣,…,∣xn∣)
- 1-范数:∥x∥1=∣x1∣+∣x2∣+⋯+∣xn∣
- 2-范数:∥x∥2=x12+x22+⋯+xn2
-
矩阵范数:∥A∥=x=0max∥x∥∥Ax∥=∥x∥=1max∥Ax∥。
∥A+B∥≤∥A∥+∥B∥
∥Ax∥≤∥A∥∥x∥
∥AB∥≤∥A∥∥B∥
同理,矩阵范数仍然有三种,设A为n阶方阵
- ∥A∥∞=1≤i≤nmaxj=1∑n∣aij∣
- ∥A∥1=1≤j≤nmaxi=1∑n∣aij∣
- ∥A∥2=方阵ATA的最大特征值
-
条件数:设A是非奇异方阵,条件数记为cond(A)=∥A−1∥⋅∥A∥
- cond1(A)=∥A∥1⋅∥A−1∥1
- cond∞(A)=∥A∥∞⋅∥A−1∥∞
- 谱条件数:cond2(A)=∥A∥2⋅∥A−1∥2=λmin(ATA)λmax(ATA)=∣λmin(A)∣∣λmax(A)∣(A是对称矩阵),λ是特征值。
第三章 迭代法解线性方程组
第1节 Jacobi迭代法
⎩⎪⎪⎪⎨⎪⎪⎪⎧a11x1+a12x2+⋯+a1nxn=b1a21x1+a22x2+⋯+a2nxn=b2……an1x1+an2x2+⋯+annxn=bn
可以把上式记为Ax=b。把A分解成D和R的和,即A=D+R。
A=⎣⎢⎢⎢⎢⎡a11a21⋮an1a12a22⋮an2……⋱…a1na2n⋮ann⎦⎥⎥⎥⎥⎤=D+R
其中,D和R分别为:
D=⎣⎢⎢⎢⎢⎡a110⋮00a22⋮0……⋱…00⋮ann⎦⎥⎥⎥⎥⎤,R=⎣⎢⎢⎢⎢⎡0a21⋮an1a120⋮an2……⋱…a1na2n⋮0⎦⎥⎥⎥⎥⎤
带入Ax=b,并令左边的x为新的迭代值,右边的x为旧的迭代值。
Dx=b−Rx⇒x(k+1)=D−1(b−Rx(x))
代入得到迭代通式:
xi(m+1)=aii1(bi−j=1∑i−1aijxj(m)−j=i+1∑naijxj(m))=aii1(bi−j=1∑n且j=iaijxj(m))(i=1,2,…,n;m=0,1,2,…)
其中m是迭代次数。对于初值,也就是x(0),需要设定一个初值。
第2节 Seidel迭代法
与前面的Jacobi迭代法通式只有一点不同,同样求解Ax=b,把A分解成A=L+D+U
L=⎣⎢⎢⎢⎢⎡0a21⋮an100⋮an2……⋱…00⋮0⎦⎥⎥⎥⎥⎤,D=⎣⎢⎢⎢⎢⎡a110⋮00a22⋮0……⋱…00⋮ann⎦⎥⎥⎥⎥⎤,U=⎣⎢⎢⎢⎢⎡00⋮0a120⋮0……⋱…a1na2n⋮0⎦⎥⎥⎥⎥⎤
然后带入Ax=b,并且令L的x和D的x为新的迭代值,令U的x为旧的迭代值
Dx=b−Lx−Ux⇒Dx(k+1)=b−Lx(k+1)−Ux(k)⇒x(k+1)=(D+L)−1(b−Ux(m))
代入得到迭代通式:
xi(m+1)=aii1(bi−j=1∑i−1aijxj(m+1)−j=i+1∑naijxj(m))
注意第一个求和只是[1, i-1]求和,然后假设我们需要求第i个xi(m+1)的值时候,我们已经把所有小于i(j<i)的xj(m+1)求解出来了,所以这里逻辑是说得通的。通过这里我们发现,跟Jacobi最大的区别是,这里求新的迭代值时候,只能串行求解,不能并行求解。
第3节 SOR方法
超松弛迭代法(successive over relaxation method)是对Seidel迭代法的一种加速方法,是解其系数矩阵为大型稀疏矩阵的方程组的一种有效方法。
x^i(m+1)=aii1(bi−j=1∑i−1aijxj(m+1)−j=i+1∑naijxj(m))
这里的x^i就是跟Seidel中的xi一样的,但是这里是引入的一个中间变量。另外,再引入一个松弛参数ω,真正的xi应该是:
xi(m+1)=(1−ω)xi(m)+ωx^i(m+1)=xi(m)+aiiω(bi−j=1∑i−1aijxj(m+1)−j=i∑naijxj(m))
如果ω>1则称为超松弛迭代法;如果ω<1则称为低松弛迭代法;当ω=1时,就是Seidel迭代法。
下面给出一些定理:
- Ax=b的系数矩阵为实对称正定且0<ω<2时,SOR法收敛。
- 如果A是三角对称正定矩阵,B1,B2分别为Jacobi和Seidel迭代矩阵,则有:
- ρ(B2)=(ρ(B1))2<1
- 最佳松弛因子:ωoρ=1+1−ρ(B2)2
- 松弛迭代矩阵 Bω 的谱半径:ρ(Bω)=ω−1,其中谱半径是指矩阵特征值的绝对值最大值,max{∣λ1∣,∣λ2∣,…,∣λn∣}
第三章 非线性方程求根
非线性方程有两类,一类是含有三角函数、对数函数、指数函数及其他超越函数的方程,称为超越方程;另一类重要的方程是:
f(x)=a0+a1x+a2x2+⋯+anxn=0(an=0)
第1节 搜索法
假设给定区间[a,b],f(x)再这个区间上连续且满足:f(a)f(b)<0
- 直接搜索:也就是从起点a开始,给定步长依次往终点b搜索。找到连续两个点xi,xi+1,但是其符号不同,所以最终结果为2xi+xi+1
- 二分法搜索:取中点 c,如果f© = 0,c就是根;如果f(a)f©<0,则根在[a,c]中;如果f(a)f©>0,则根在[c,b]中;继续步骤
第2节 迭代法
只需要把f(x)=0改写成x=ϕ(x)的形式,然后迭代函数:xk+1=ϕ(xk),现在需要考虑一下这种迭代是否收敛。
-
压缩印象定理:若函数ϕ(x)在区间[a,b]上具有一阶连续的导数,且满足:
- 封闭性,即当x∈[a,b]时,ϕ(x)∈[a,b]
- 压缩性,存在正常数L<1(L称为压缩系数),使得对任意x∈[a,b]有∣ϕ′(x)∣≤L,则
- 方程x=ϕ(x)在[a,b]上有唯一实根x∗
- 对任意x0∈[a,b],k→∞limxk=x∗
- 误差事后估计式:∣xk−x∗∣≤1−LL∣xk−xk−1∣
- 误差事前估计式:∣xk−x∗∣≤1−LLk∣x1−x0∣
- k→∞limxk−x∗xk+1−x∗=ϕ′(x)
-
设x=ϕ(x)在区间[a,b]有根x∗,当x∈[a,b]时,∣ϕ′(x)∣≥1,则对任意初始值x0∈[a,b]且x0=x∗,迭代公式xk+1=ϕ(xk)发散
第3节 牛顿法
f(x)=f(xn)+f′(xn)(x−xn)+2!f′′(xn)(x−xn)2+…
取泰勒公式前两项来替代f(x),并且当f’(x)不为0时有:
xn+1=xn−f′(xn)f(xn)
牛顿法求重根也是收敛的,不过是线性收敛。
第4节 弦线法
设xn,xn−1是f(x)=0的两个近似根,它们对应的函数值为f(xn),f(xn−1),过两点做直线,直线方程如下
p(x)=f(xn)+xn−xn−1f(xn)−f(xn−1)(x−xn)
用直线方程替代函数,那么就相当于求解p(x)=0的解了
xn+1=xn−f(xn)−f(xn−1)xn−xn−1f(xn)
第四章 插值法
第1节 插值定义
设f(x)是定义在区间[a,b]上的函数,x0,x1,x2,…,xn是区间[a,b]上n+1个互异的点,若存在一个简单函数pn(x),满足:
pn(xi)=f(xi)=yi
pn(x)是插值函数,求pn(x)的方法称为插值法
第2节 Lagrange插值
2.1 线性插值
两个点(x0,y0),(x1,y1)过两点做直线,所以一次插值也称为线性插值。
p1(x)=y0+x1−x0y1−y0(x−x0)
2.2 抛物插值
三个点(x0,y0),(x1,y1),(x2,y2)过三点做抛物线,所以抛物插值也称为二次插值。
p2(x)=y0(x0−x1)(x0−x2)(x−x1)(x−x2)+y1(x1−x0)(x1−x2)(x−x0)(x−x2)+y2(x2−x0)(x2−x1)(x−x0)(x−x1)
2.3 一般情形
lj(x)=k=0k=j∏nxj−xkx−xkpn(x)=j=0∑nli(x)yi
第3节 牛顿插值公式
3.1 差商的概念
f(x)关于xi,xj的一阶差商:记作f[xi,xj]=xi−xjf(xi)−f(xj),f(x)关于xi,xj,xk的二阶差商:记作f[xi,xj,xk]=xk−xif[xj,xk]−f[xi,xj]。一般地,k阶差商为:f[x0,x1,…,xk]=xk−x0f[x1,x2,…,xk]−f[x0,x1,…,xk−1]=m=0∑ki=0i=m∏k(xm−xi)f(xm),并且任意改变节点次序,k阶差商值不变。
3.2 牛顿插值
将n次插值多项式写成如下形式:
Nn(x)=a0+a1(x−x0)+a2(x−x0)(x−x1)+⋯+an(x−x0)(x−x1)…(x−xn−1)=a0+i=1∑n(aik=0∏i(x−xk))
由插值条件:
Nn(x0)=f(x0),Nn(x1)=f(x1),…,Nn(xn)=f(xn)
可得方程:
⎩⎪⎪⎪⎨⎪⎪⎪⎧a0=f(x0)a0+a1(x1−x0)=f(x1)……a0+a1(xn−x0)+⋯+an(xn−x0)…(xn−xn−1)=f(xn)
求解方程:
a0=f(x0),a1=f[x0,x1],a2=f[x0,x1,x2],…,an=f[x0,x1,x2,…,xn]
第五章 数值微分
第六章 数值积分
