
目录
-
前置知识
- 1、URL
- 2、http请求
- 3、http响应
- 4、爬虫步骤
-
浏览器抓包知识
- 1、打开调试窗口
- 2、详解请求头参数
-
python实现简单抓包
- 1、requests模块使用
- 2、正则表达式
前置知识
1、URL
URL是统一资源定位表示符号,当然,还有URI,URN的概念,这里就不细究这两个这三者区别,因为我们重点是讨论URL是什么,以及如何解析URL就行。
完整的URL如下,方括号表示可以省略的,圆括号表示不能省略,尖括号表示浏览器默认会加上去的。空格只是为了讲解,URL是不能有空格的。不仅如此,URL只能有英文字母,阿拉伯数字和某些英文标点符号组成。
-
< 协议 > 😕/ ( 域名或IP ) : < 端口 > / 【 [ 路径信息 ] / [ 文件名 ] ? [ 参数部分 ] # [ 锚部分 ] 】
< 协议 >:指明何种协议,如
http,https,ftp等等,这里只讨论http,写爬虫代码时,最好指定为http。(域名或IP):域名地址或者IP地址都可以,不了解的可以搜索域名地址和IP地址是什么。大白话就是网址(不完全等同),如
baidu.com。<端口>:端口地址,不了解的也搜索一下,http协议是80端口,通常省略。
[路径信息]:请求的路径信息,即需要请求的资源在服务器的什么位置,通常抓包获得。
[文件名]:请求的文件名是什么,通常抓包获得。
[参数部分]:请求参数,通常抓包获得,一般叫做字符串参数,为了区别于请求数据中的参数。这里需要着重讲一下
1)通常是以 键=值 的形式表示单个,用
&连接多个参数。2)如:
quest=http&id=1234&pass=223)上述就有三个参数(quest = http,id = 1234,pass = 22),两两直接用
&连接起来[锚部分]:不重要,反正也是抓包获得。
特殊字符串表示:前面说到URL只能由英文字母,阿拉伯数字和某些英文标点符号组成。那么不是这些的怎么表示呢?
答:采用 URL-ASCII 编码格式进行编码。URL允许出现的字符有:
-,.,_,~,注意都是英文字符。保留的字符有:
! * ' ( ) ; : @ & = + $ , / ? # [ ]这十八个,都是英文字符,如等号用来连接键与值。
2、http请求
格式如下:
请求方式 URL 版本号【回车换行符】
键: 值 【回车换行符】
....(重复键:值)
键: 值 【回车换行符】
【回车换行符】
主体内容
上述内容太混乱了,没关系,一行一行来看
1、第一行:
请求方式:包括
POST和GET,当然,还有其他,常用这两种。注意,都是大写。URL:上述解释中的URL,一般指包括路径信息及其后面部分,而没有前面部分。至于IP地址这些,要么在请求表头中用参数给出,要么直接不给,主要是IP地址和端口不是应用层的实体。
版本号:这个也不重要,现在应该是
HTTP/1.1。
- 2、第二行及之后几行
这一部分叫做请求标头的参数部分,(第一行也是请求标头的一部分),通常有很多参数组成,每个参数都是 键: 值的形式。一行一个参数。
-
3、主体内容,
GET请求一般没有主体内容,但是POST一般有。 -
4、【回车换行符】:即
\r\n。注意,主体内容与请求标头中间额外多一个空行,所以额外多一个回车换行符。
下述是一个POST请求示例:(不完整)
POST /eportal/?c=ACSetting&a=Login HTTP/1.1
Host: p.t.edu.cn:8032
Referer: http://p.t.edu.cn/
User-Agent: Mozilla
DDDDD=%2C0&upass=1&v6ip=
3、http响应
格式如下:
版本 状态码 短语【回车换行符】
键: 值【回车换行符】
.....(重复上一行)
键: 值【回车换行符】
【回车换行符】
主体内容
解释如下:
-
版本:和请求一样,这里不额外解释
-
状态码:此条响应的状态,一般如下:
1xx:表示通知消息,如还在处理上述请求,有些请求需要进行复杂的运算或处理,仍然需要等待
2xx:表示成功了,常见的是 202
3xx:表示重定向,需要跳转到另一个网址
4xx:表示客户端错误,如请求的报文无法解析,常见的 404
5xx:表示服务器的错误,如服务器没法工作了。
-
短语:对上述状态码的解释
如Accepted是对202状态的解释。
如Not Found是对404状态的解释。
-
主体内容,返回的响应内容在此。
4、爬虫步骤
首先确定请求方法,然后根据请求方法寻找请求参数,然后使用代码进行请求。寻找请求方法和请求参数的过程叫做抓包,用代码进行请求的过程叫做爬取内容。请求方法常见的是POST和GET
-
GET请求
需要找到请求标头,请求字符串参数。
确定是否需要https,是否需要代理,是否需要cookie等
-
POST请求
需要找到请求标头,请求字符串参数,请求数据。
确定是否需要https,是否需要代理,是否需要cookie等。
浏览器抓包知识
1、打开调试窗口
要么空白地方右键,然后点击属性。要么按F12。打开如下页面,点击网络(Network)就算成功。
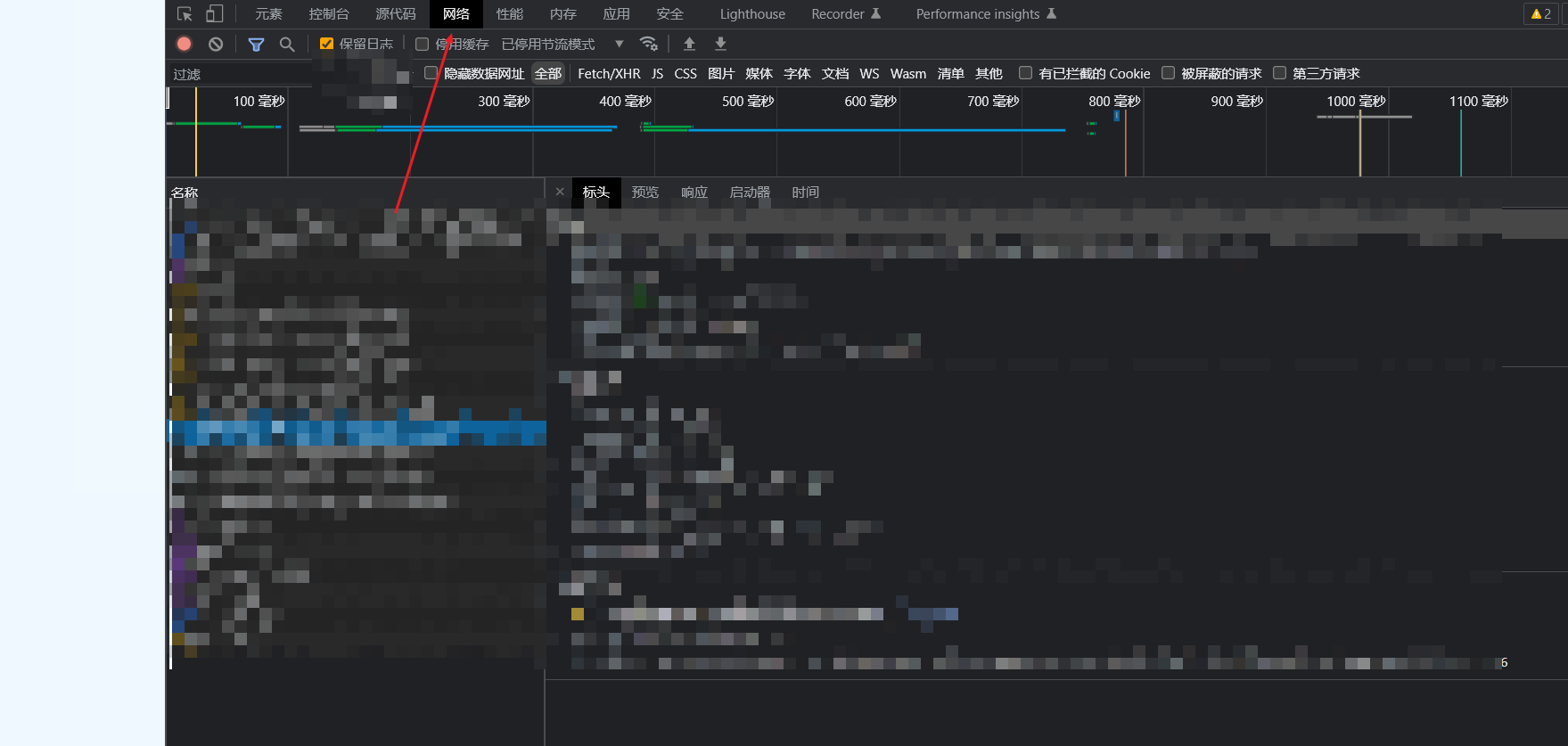
简要介绍了主体界面构成
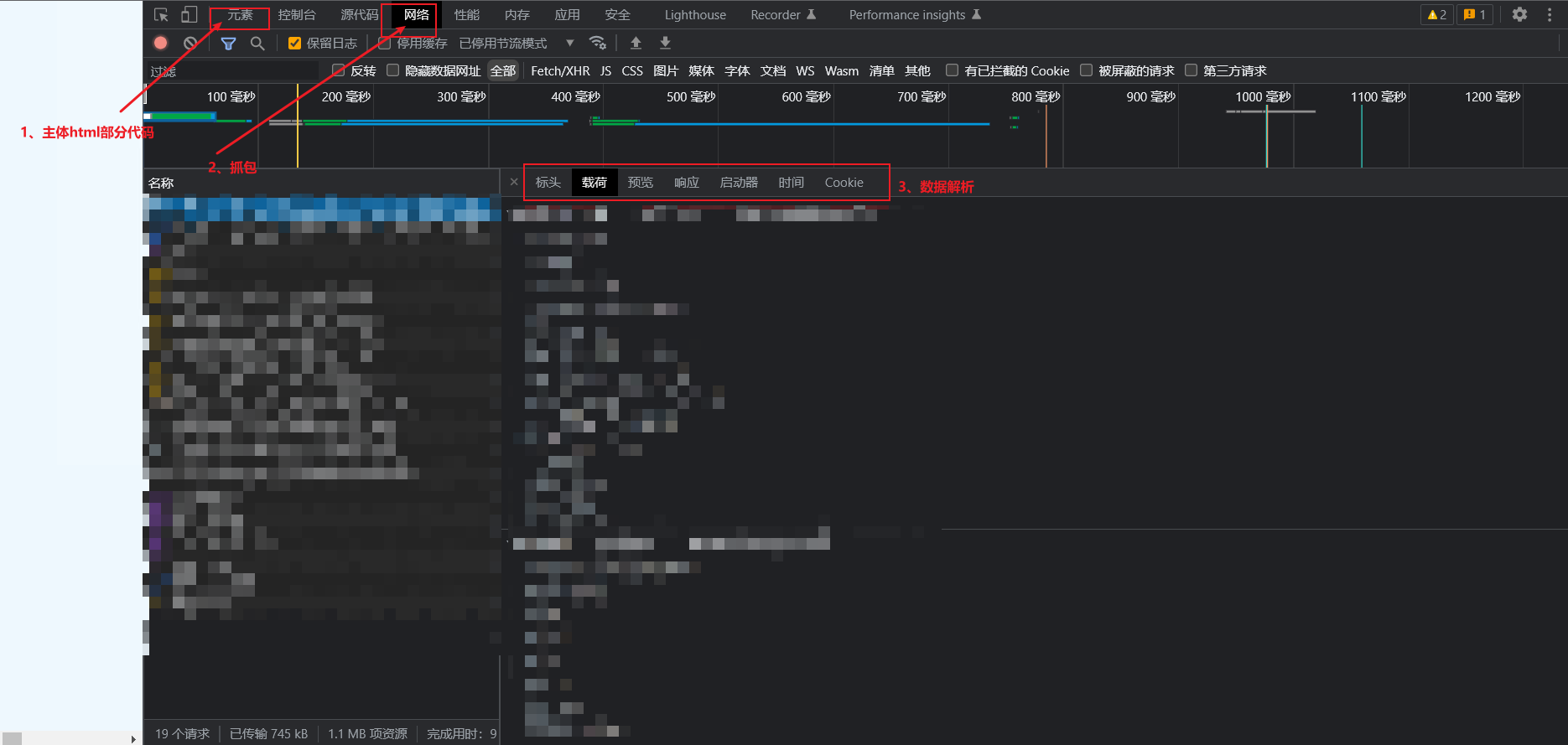
-
1、主体html部分,一般用来索引到html部分的位置,注意
 左边箭头,可以直接点击页面上的点,确定html元素代码位置。具体做法是,点一下这个箭头,然后点击页面上的元素(如输入框),即可确定代码位置。
左边箭头,可以直接点击页面上的点,确定html元素代码位置。具体做法是,点一下这个箭头,然后点击页面上的元素(如输入框),即可确定代码位置。 -
2、抓包部分,最常用的部分,分析分析数据的地方。
 这个红色的圆圈,表示停止抓包。红色右边圆圈斜杠表示请求当前抓到的内容。**全部 | Fetch/XHR JS CSS…**用来过滤抓取的内容,有时候只需要图片的包,就点击图片,有时候只想抓取提交的表单数据,就点击清单。如果内容不多,可以点击全部(ALL)来全部显示,没必要过滤。
这个红色的圆圈,表示停止抓包。红色右边圆圈斜杠表示请求当前抓到的内容。**全部 | Fetch/XHR JS CSS…**用来过滤抓取的内容,有时候只需要图片的包,就点击图片,有时候只想抓取提交的表单数据,就点击清单。如果内容不多,可以点击全部(ALL)来全部显示,没必要过滤。 -
3、数据解析部分
标头:请求头部分的内容;
载荷:字符串参数和主体内容部分,GET请求只有字符串参数,POST请求会有请求表单数据。
预览和响应:因为一个请求对应于一个响应,这里都是只响应的内容;其中,预览代表是人性化的展示了相应内容,响应只是把原始数据给你展示。
查看源代码:查看原始数据,而不是人性化的给你显示数据。
2、详解请求头参数
Accept: text/css,*/*;q=0.1
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Connection: keep-alive
Cookie: program=null
Host: p.t.edu.cn
Referer: http://p.t.edu.cn/
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.115 Safari/537.36
这里只显示了几个重要的参数。
-
Accept:指的是,请求内容是什么。如这里是指请求类型为text的css数据,常见的还有test/html,一般直接复制到代码中即可,或者可以省略。(我指的不是复制这里的到代码,而是复制自己抓包时的内容到代码) -
Accept-Encoding:编码格式,一般直接复制到代码,或者省略。 -
Accept-Language:请求的语言,一般省略或者复制到代码。 -
Connection:众所周知,http是建立在TCP之上的,如果发一次http请求就需要进行一次TCP三次握手连接与四次挥手释放,那么会给网络带来很大的开销,所以使用这个参数告知服务器是否要保持我的TCP连接性。 -
Cookie:众所周知,
HTTP是具有单次连接性,即任何两次连接之间没有联系,是相互独立的。但是,我们常常登录某个网站之后可以自由的操作自己的账户,而不是每次操作账户都要进行提交账密操作,正是因为这个
Cookie的作用,用来记录我们的连接性,使得两次连接之间有了关联。通常省略,复制也没有,反正有时间限制的,而且每次可能会变。对于一般的代码库,应该有能够保持
Cookie的工具。 -
Host:请求的主机,前面说了,URL中没有域名,那么域名就在这了,通常复制。很多网站都没有这一项。 -
Referer:重中之重,注意,我没有打错字,之所以是错的原因,当初创立这个键值的时候,就是打错了的。所以一直沿用至今,就是这么离谱。为什么说这个重要呢?
因为,很多网站不希望你从某些地方跳转过来,所以会检验这个,有些网站需要你从指定网站跳转到他们网站,也是用这个来检验。比如我们学校的校园网登录系统,就是不希望你从其他地方跳转过来。这个是我们伪造的重点
-
User-Agent:重中之重,在是浏览器和系统表示,很多时候,网站不希望我们用爬虫去爬取,所以通过这个检验请求是谁发来的。
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.115 Safari/537.36这个是Windows的chrome的标识,大家应该都是一样的。 -
其他:具体网站具体分析
-
至于这些请求头,谁给我们加到,一般是网站的
js代码和浏览器的默认加。我们要做的,就是用代码伪造这些数据,把我们伪造成网站希望我们访问的方式来访问,听着有点绕。比如,把我们伪造成浏览器来抓取数据。
Python实现简单抓包
1、requests模块使用
1)安装requests模块
打开你的命令行,键入如下命令
pip install requests
2)简单介绍
讲得非常浅显,用来下载图片或者自动登录还可以。
import requests as rq # 导入代码包
# 我的理解是创立一个请求工具箱
# 这个会维持Cookie,就像我上面所说的一样
# 之后使用这个工具箱进行操作
tool = rq.session()
# 设置是否进行SSL验证
# 也就是是否需要验证https
# 这个得看自己决定,看看https是什么样的,有什么用
# 当然,一般可以设置为False
verify=False
# 请求主机,一般就是Host字段的值
# 我这里是百度
url="https://baidu.com"
headers={ # 设置请求头
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/"
"537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
"Referer": "https://baidu.com"
}
proxies={ # 设置代理
"http": None,
"https": None
}
params={ # 设置字符串参数
}
# 设置请求表单,一般在post请求中常用到
# 我请求百度的页面,用的是post请求
data={ # 设置请求表单
}
# 发送get请求,得到get响应
responseGet = tool.get(url=url, params=params, headers=headers, verify=verify, proxies=proxies)
# 发送post请求,得到post响应
responsePost = tool.post(url=url, data=data, headers=headers, verify=verify, proxies=proxies)
# 响应的主体内容一般都是二进制内容
# 需要进行对应解析,这个好像需要设计到python知识
# 我的评价是,不是这里的重点
# 解析响应
# 1、假如响应是文本数据,如html文本
response = responseGet
response.content # 这个是内容,是二进制编码
response.content.decode("gbk") # 使用gbk解码,不加参数就是utf-8解码
# 2、假如响应是图片数据
with open("1.png", "wb") as f:
f.write(response.content) # 直接以二进制写入文件
# 3、假如响应是表单数据
dat = json.loads(response.content.decode()) # 返回的就是一个字典数据了
2、正则表达式
正则表达式有什么用呢?
假如,你需要下载一个页面中的所有图片,虽然我们 这里的箭头可以确定你要的图片,如果一张一张点,是不是有点太慢了,跟手动下载有什么区别。所以,我们需要用到正则表达式,用来匹配一定规则的字符串。因为我们知道,图片是渲染出来的,本质在html中仍然以字符串存在,如:
这里的箭头可以确定你要的图片,如果一张一张点,是不是有点太慢了,跟手动下载有什么区别。所以,我们需要用到正则表达式,用来匹配一定规则的字符串。因为我们知道,图片是渲染出来的,本质在html中仍然以字符串存在,如:<img src="http://example.com/momo.png" width="300px">。
如果我们雇佣一个人来找这些图片,你会告诉他如下知识:“
按照使用<img>标签圈起来的,里面是以src=开头的后面那串字符串。而且,图片的连接是以http://或者https://并且以.png、.jpeg、.git或者.jpg结尾的那串字符串。请给我把所有的找出来。
”。
所以,正则表达式可以帮我们干这个事情。详细正则表达式请看正则表达式教程
import re # 导入正则表达式包
html = response.content # 这个是请求的html内容,也就是网页,本质是字符串
# 我们需要在html中需要所有的图片链接
# 我们得告诉我们的雇员一个寻找标准
standard = "<img\\ssrc=\"(.*?)\".*?>"
# 显然,我们认为<img>标签里的就是图片,我们直接简化了我们的标准
# 不需要管是不是http开头,是不是.png结尾的字符串
# 简单解释:\\s这三个字符代表空格
# .*?: 代表任意字符串,并且保证匹配的同时,字符串的长度越小越好
# 进行匹配
dst_list = re.findall( standard, html) # 返回列表