
增
最重要的一条命令insert
insert into `table_name` # 插入到表 table_name 中
(`col_name1`, `col_name2`, `col_name3`, ..., `col_namei`) # 列名(字段名),如果插入的是所有列,那么可以省略
values
(data_1_1, data_1_2, data_1_3, ..., data_1_4), # 第一条数据,可以插入单条或多条数据
(default, data_2_2, data_2_3, ..., data_2_4), # 如果是自增数据,那么就可以使用 default 来保证数据自动增1,而不需要人为设置
...
(data_n_1, data_n_2, '2025-02-18', ..., 'this is string'); # 使用单引号或者双引号 '' 来插入字符串,最后一列不要加逗号
增删改查中,增应该是最简单的,因为后面的删改都需要进行条件判断,而查则是最难的。
删
下面是删除的最基本语法
delete from `database.table` # 所有的这种 `database.table` 可以写成 `table` 但是需要进入到数据库中
where <条件>; # 这里是条件,详细条件用法需要看后面
# 比如下面:
delete from `table` where id = 3; # 删除 id 为 3 的那一行数据,这里是单个等号
改
下面是更改的最基本用法
update `database.table` # 使用哪张表
set `col_name` = col_data # 更新的数据
where <条件>; # 这里的条件详细用法看后面
查
查应该是最复杂的用法,但是其实只涉及到一条最基础的命令select ... from table ...; 难点在于两个省略号,内容太多了。
接下来还是以测试用例来一步步学习,这个样例一共两张表,创建表代码如下:
CREATE TABLE IF NOT EXISTS Covid_total (
`Country_id` INT NOT NULL AUTO_INCREMENT,
`Country` VARCHAR(22) CHARACTER SET utf8,
`Continent` VARCHAR(17) CHARACTER SET utf8,
`Population` INT,
`Total_cases` INT,
`Total_deaths` INT,
`Total_recovered` INT,
`Total_active` INT,
PRIMARY KEY (Country_id)
);
CREATE TABLE IF NOT EXISTS Covid_month (
`Record_id` INT NOT NULL AUTO_INCREMENT,
`Date` DATETIME,
`Country` VARCHAR(32) CHARACTER SET utf8,
`Confirmed` INT,
`Deaths` INT,
`Recovered` INT,
`Active` INT,
`New_cases` INT,
`New_deaths` INT,
`New_recovered` INT,
`Continent` VARCHAR(21) CHARACTER SET utf8,
PRIMARY KEY (Record_id)
);
Ps:表的来源是,技术蛋老师
简单查询
# 查询所有的,这个速度非常慢
select * from Covid_total;
# 只查询这两列,内容多,速度也慢
select
`Country_id`,`Total_cases`
from Covid_total;
# 相比于上一句,仅仅是显示重命名了而已,显示 c_id 和 tc
select
`Country_id` as `c_id`, # 显示 c_id 而不是 Country_id
`Total_cases` as `tc`
from Covid_total;
# distinct 是去重,查询结果均相同的去重,比如下面 所有 Continent = Country 的只显示一个
select distinct
`Continent`, `Country`
from Covid_total;
# 对查询结果排序,ASC是升序,DESC是降序
select
`Country_id`, `Country`, `Total_deaths`
from Covid_total
order by
`Total_deaths` ASC;
# 还可以多列排序,即,从第一个条件开始排序一直到最后一个条件
select
`Country_id`, `Country`, `Total_deaths`
from Covid_total
order by
`Total_deaths` ASC,
`Country_id` DESC; # 先按照 Total_deaths 升序,再按照 Country_id 降序
条件查询
支持=,!=,<,>,>=,<=,and,or,not,between<val1>and<val2>(val1<=val<=val2),IN,IS,LIKE等符号
值得注意的是,NULL的判断应该是使用:is NULL和is not NULL,任何值与NULL做比较,返回的仍然是NULL,还有一个运算符<=>,当两值相等或两值为NULL才返回true,否则返回false
# 条件查询应该是如下形式,注:加上了之前的用法,之前的用法不是必须的,只是看看一个 select 是怎么一步步增加的
select [distinct]
<col_name> [as `new_name`], ...
from `table_name`
where # 这一部分才是条件查询
<条件> # 这是条件
[order by
<排序字段>]
;
- 基本的比较运算符用法以及逻辑运算符用法:
# 1.1 普通比较
select
`Country_id`, `Country`, `Total_deaths`
from Covid_total
where
`Country_id` <= 100 # 只看 id 不大于 100 的数据
;
# 1.2 逻辑运算符
select
`Country_id`, `Country`, `Total_deaths`
from Covid_total
where
`Country_id` <= 100 # 只看 id 不大于 100 的数据
and `Total_deaths` between 9252 and 9889 # 而且只查看 Total_deaths 在 [9252, 9889]之间的
; # 如果 between and 的两个数字大小顺序错了不会报错,只会 没结果
# 1.3 is 比较
select
`Country_id`, `Country`, `Total_deaths`
from Covid_total
where
`Total_deaths` is null # 查询为 null 的
;
# 1.4 in 运算
select
`Country_id`, `Country`, `Total_deaths`
from Covid_total
where
`Total_deaths` IN (9252, 9889) # 枚举查询,这样会比较慢,更加推荐使用 = 查询,查询等于 9252 和 9889 的
;
like查询,这其实是模糊搜索,即使用通配符_和%:_表示任意单个字符,%任意多个字符
select
`Country_id`, `Country`, `Total_deaths`
from Covid_total
where
`Total_deaths` like '9___' # 注意使用单引号包裹,而且这个不仅可以查询字符串,也可以查询数字,比如查询 9xxx 的数字
;
select
`Country_id`, `Country`, `Total_deaths`
from Covid_total
where
[binary] `Country` like 'g%' # 查询 G 开头的国家,默认不区分大小写的,除非在前面加上 binary,又或者建表的时候在列属性那里加上 binary
;
- 正则查询,上面的
like过于简单,并不能满足所有需要,所以其实还可以利用正则表达式来查询,需要用到RLIKE或者REGEXP,两者效果完全一样,用法也一样。
select
<数据列>
from <表>
where <列> <RLIKE / REGEXP> '正则表达式串' # 随便写 rlike 或者 regexp 都可,查找符合正则表达式的结果
;
# 下面是满足 A 开头,然后有三个任意字符,然后一个字符是 a 的字符串,后面任意
select `Country`
from `Covid_month`
WHERE `Country` RLIKE '^A...a'; # 和 ^A...a.*?' 效果一样,不需要把整个串的匹配模式都写出来,可以只写其中一部分的匹配模式
聚合查询
聚合查询是指,利用SQL的库将查询结果聚合的一种查询模式,比如下面这个例子
select COUNT(*) from `Covid_total`; # 这个就是统计查了多少行,作用就是返回表中的数据数量,包括 NULL
select COUNT(`Country`) from `Covid_total`; # 跟上面这个作用完全一样
除此之外,还有以下一些常用的查询:
select SUM(`Total_deaths`) from `Covid_total`; # sum函数是计算数值型列的总和的,一定需要数值型,实测,Date 型也可以
AVG() # 平均值
MAX() # 最大值
MIN() # 最小值
COUNT(DISTINCT `col_name`) # 对某一列去除后计算数量
分组查询
分组查询涉及到的关键字是:group by,前面有提到,关系型数据库会有一对多的情况发生。比如一个学生对应很多班级,那么就可以按照班级分组来查询。
即:根据某列进行分组,然后再查询统计
select
`Country`, COUNT(*)
from `Covid_total`
group by `Country`; # 按照 `Country` 列进行分组,也就是 Country 相同的数据会分成一个组
# 当然,group by 后面其实可以跟多列,其结果是什么呢?
# 只有多列都相同的才会被分到一个组,但凡有一列不同,就是两个组了
select
`Total_deaths`, `Population`, COUNT(*)
from `Covid_total`
group by `Total_deaths`, `Population` # Total_deaths 和 Population 都相同的会分成一个组
;
值得注意的是:select后面跟的列,只能是group by后面跟的列的一个子集。即group by Total_deaths, Population只能查询Total_deaths, Population这两列或者这两列中的一列。
这是由于,我们已经按照这两列分组了,但是一个组内,其他列的值并不唯一,所以数据库不知道返回什么值。
分组查询过滤
分组查询之后,可能还是需要对结果进行过滤,那么就可以用having关键字来,其基本用法如下:
select
<聚合查询> [, <列名>...]
from <表名>
group by <列名>
having <条件>
;
-- 根据前面的内容已经知道,where 条件其实是对最终结果中的列进行过滤(不分组的情况下)
-- 那么同样的,having 就是对分组之后的结果的列进行过滤
比如下面这个例子,查询这个月每个国家的死亡人数
select
`Country`, SUM(`Deaths`)
from `Covid_month`
group by `Country`
;
-- 然后只看大于 6000 的结果
select
`Country`, SUM(`Deaths`)
from `Covid_month`
group by `Country`
having SUM(`Deaths`) > 6000;
;
多表查询-笛卡尔乘积查询
很多时候,两张表里面的数据往往是有关联的,比如学生表和班级表,班级表会记录当前班级的班主任,学生表中就没必要记录了,那该如何去查询每个学生的班主任是谁呢?
- 简单乘积查询:显然查询数量是两张表数量的乘积
select * # 所有的列(这两张表的)都会拼接起来
from `Covid_total`, `Country_month`; # 每一张表的数据都会对应另一张表的所有数据
# 上面查询是最简单的多表查询,出来的结果是:
# 假如表1的第i列数据记为 b1_i,表2的第j列数据记为 b2_j
# 表1总共 m 行数据,表2总共 n 行数据,查询结果就是 m*n 行数据
# 查询结果如下:
# b1_1, b2_1
# b1_1, b2_2
# ....
# b1_1, b2_n
# b1_2, b2_1
# b1_2, b2_2
# ....
# b1_2, b2_n
# ....
# b1_m, b2_1
# b1_m, b2_2
# ....
# b1_m, b2_n
select count(*) FROM `Covid_month`; # 4967
SELECT COUNT(*) FROM `Covid_total`; # 206
SELECT COUNT(*) FROM `Covid_month`, `Covid_total`; # 1023202
# 如果不想选每一列,只想选择表1的某几列,表2的某几列呢?
select `table1`.`col1` as `name1`, `table1`.`col2` as `name2`, `table2`.`col4` as `name3`
from `table1`, `table2`;
- 对应乘积查询,比如查询目的是,一个学生对应一个班级,然后想看看这个班级对应的信息是什么。
select
`Covid_month`.`Date` as `Date`,
`Covid_month`.`Country` as `Country`,
`Covid_total`.`Country` as `Country`,
`Covid_total`.`Population` as `People`
from `Covid_month`, `Covid_total`
where `Covid_month`.`Country` = `Covid_total`.`Country` # 只查询国家相同的时候
;
# 发现上面写那么多 `Covid_month`. 或者 `Covid_total`. 太麻烦了
# 可以对表也重命名
# 将上面改一下,也就是说,在 from 字段重命名的表,直接可以用新名字来指代表,这样会少写很多东西,而且带块也会小很多
select
`cm`.`Date` as `Date`,
`cm`.`Country` as `Country`,
`ct`.`Country` as `Country`,
`ct`.`Population` as `People`
from `Covid_month` as cm, `Covid_total` as ct
where `cm`.`Country` = `ct`.`Country` # 只查询国家相同的时候
;
多表查询-内连接查询
需要使用inner join关键字
其形式如下:
select <查询的列>,...
from <主表>
inner join <副表> on <条件>
;
解释如下:
- 先从主表中查询所有结果
- 再从副表查询所有满足
<条件>的结果,并连接起来 - 只显示
<查询的列>... - 并且显示的结果,只会包含两张表中条件部分都存在的结果,即如果一张表中没有另一张表的
Country,那么就查询结果不会显示
# 下面的功能跟上面多表查询的功能一样,但是这个速度在大量数据的情况下比上面的快多
# 并且也可以注意到,在 inner join 中也可以重命名表
select
`cm`.`Date` as `Date`,
`cm`.`Country` as `Country`,
`ct`.`Population` as `People`
from `Covid_month` as cm
inner join
`Covid_total` as ct on ct.`Country` = cm.`Country` # 只有当两个表的`Country`相等时才连接
;
多表查询-左右全连接查询
不妨把主表想象其放在左边,副表想象其放在右边。左连接查询(left join)和右连接查询(right join)会发生什么呢?
- 前面的内连接
inner join其实就是在查找两张表都包含的Country。 - 左连接
left join就是查找主表所有的结果,如果副表没有这个结果,那么就显示为NULL - 右连接
right join就是查找副表所有的结果,如果主表没有这个结果,那么就显示为NULL - 全连接
full join就是查找两张表都有的结果,如果一张表的Country不在另一张表中,就显示NULL - 合理运用这些连接以及
NULL值,还可以求更多的集合运算 - 这里说的多表查询其实只涉及两张表,那么如何进行三张表或更多表的真正多表查询呢?那就是两张两张的查询。
下图很好的说明了这种关系
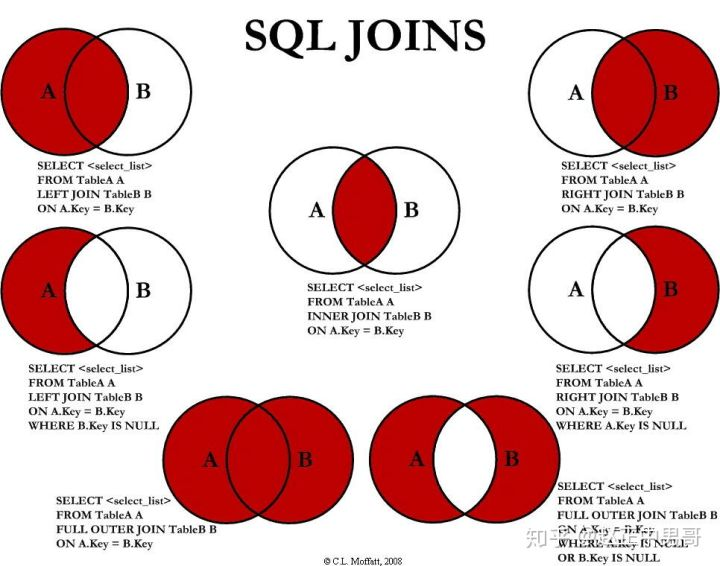
UNION联合查询
union [all]关键字可以对两个或多个select语句进行联合查询,但是需要注意的是,每个select语句必须保持相同的列且列的类型相同。
union会默认会数据进行去重,union all则不会对数据去重。
select `Total_deaths`, `Country` from `Covid_total` where `Total_deaths` = 162804 # 162804是查的最大的数量
UNION
select `Deaths`, `Country` from `Covid_month` where `Deaths` = 148011 # 148011是查的最大的数量
;
# 显示结果是 Total_deaths, Country,列名是第一个 select 语句的,
Total_deaths, Country
162804, USA
148011, US
尽量使用union all来查询,然后在应用程序中去重会好一点。
LIMIT限制查询结果
一次性查询的结果太多了,那么可以通过LIMIT和OFFSET来限制查询结果,比如我们只想要最大的5条结果,或者从前往后的第5-10条结果
select
`Country` as `国家`, `Total_deaths` as `总人数`
from `Covid_total`
order by `总人数` desc # 对总人数进行排序
limit 10 # 只显示 10 条结果
;
select
`Country` as `国家`, `Total_deaths` as `总人数`
from `Covid_total`
order by `总人数` desc
limit 5 offset 5 # 只显示5条结果,但是忽略前面5条结果
;
顺序
select语句分为书写顺序和执行顺序。
书写顺序如下:
SELECT [DISTINCT | ALL] # 选择某表的某些列,可以选择是否去重
<列名...> | <聚合函数> # 选择出来列,可以用 as 重命名
FROM <表名> # 选择的表名,可以用 as 重命名
[WHERE <条件...>] # 分组前的过滤
[GROUP BY <列名...>] # 分组的列名,将对所有处于同组的进行
[HAVING <条件...>] # 分组后的过滤
[ORDER BY <结果列...> [, ...] ASC|DESC] # 对总的结果进行排序
[LIMIT <行数> [OFFSET <偏移>]] # 限制排序后的输出结果
[UNION [ALL]...] # 开启第二张表的查询
[其他 SELECT 子句 ...]
;
执行顺序如下:
FROM 和 JOIN # 单表和多表查询
WHERE # 分组前过滤
GROUP BY # 分组
HAVING # 分组后过滤
SELECT # 选择输出的列
ORDER BY # 对结果进行排序
LIMIT # 对结果进行限制输出
```mysql
SELECT [DISTINCT | ALL] <列名...> | <聚合函数> FROM <表名> [GROUP BY <列名...>] [HAVING <条件...>] [ORDER BY <结果列...> [, ...] ASC|DESC] [LIMIT <行数> [OFFSET <偏移>]] [UNION [ALL]...] [其他 SELECT 子句 ...];