
Redis数据类型与数据结构
Redis有String, List, Hash, Set, Zset, BitMap, HyperLogLog, GEO, Stream共八种类型,其中,前面五种比较常用。
而Redis中,实现这几种数据类型的数据结构有SDS, 链表, 压缩链表, 哈希表, 整数集合, 跳表, quicklist, listpack,其中,后两种是新版本Redis才用的。
其对应关系如下所示:
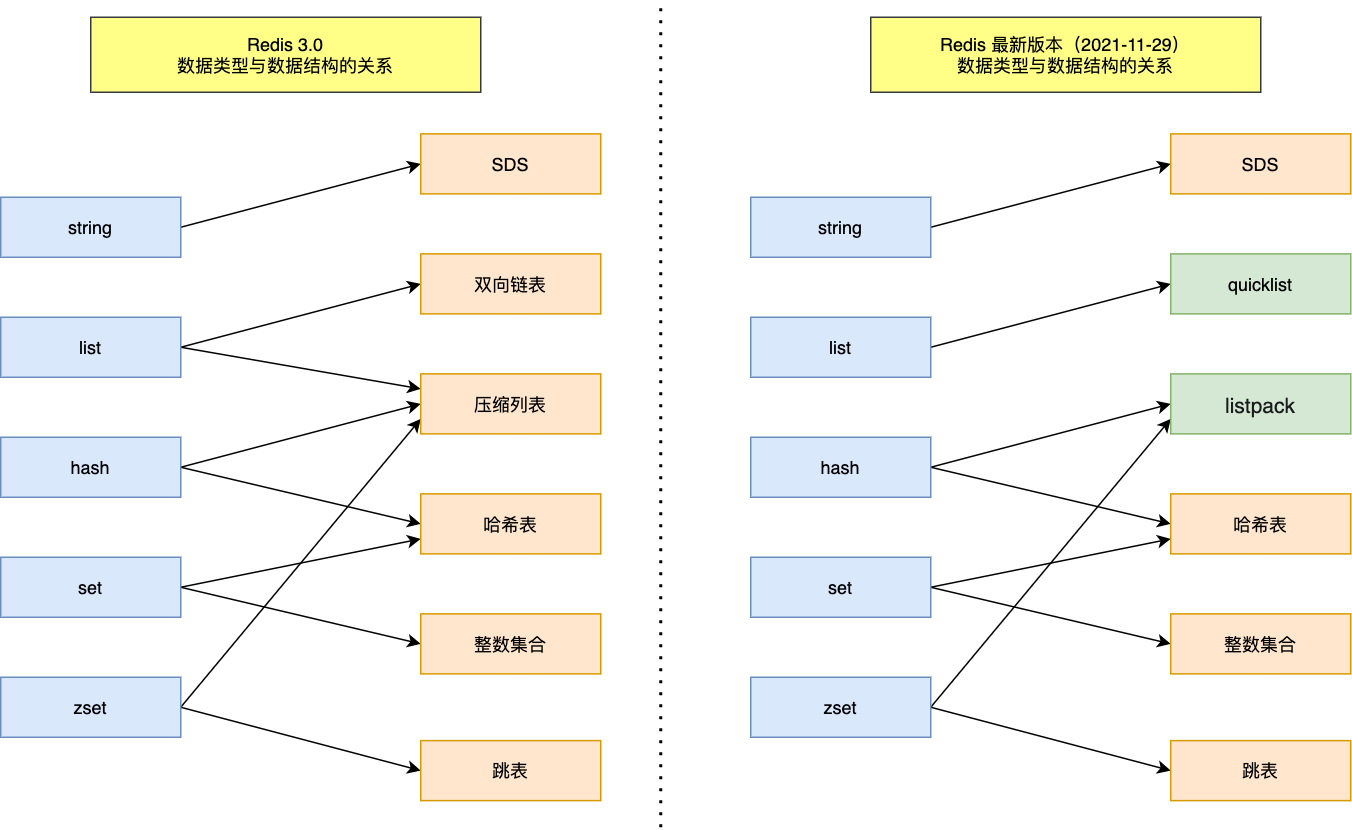
PS:图片来源于小林coding
数据结构详解
SDS
简单动态字符串(sds)
// 下面是一个简单的示意代码:
typedef struct {
int len; // 字符串长度,类似于实际长度
int alloc; // 分配空间,类似于容量
unsigned char flags; // 字符串的类型,包括 sdshdr5, sdshdr8, sdshdr16, sdshdr32 和 sdshdr64
char buf[];// 实际的数据,不仅包括字符串,还可以包括二进制数据
} sds ;
// sdshdr16 和 sdshrd32 如下:__attribute__ ((__packed__))是告诉编译器不要内存对齐
struct __attribute__ ((__packed__)) sdshdr16{
uint16_t len;
uint16_t alloc;
unsigned char flags;
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32{
uint32_t len;
uint32_t alloc;
unsigned char flags;
char buf[];
};
优点如下:
- $O(1)$获取字符串长度
- 不会发生缓冲区溢出,因为有剩余容量检测
alloc-len - 节省内存空间,可根据
flags来分配不同的内存空间
链表
// 下面是一个简单的示意代码:就是一个简单的双向链表
typedef struct listNode{
struct listNode* prev;
struct listNode* next;
void* value;
} listNode;
typedef struct list{
struct listNode* head; // 头节点
struct listNode* tail; // 尾节点
void *(*dup)(void* ptr); // 节点复制函数指针
void (*free)(void* ptr); // 节点释放函数指针
int (*match)(void* ptr, void* key); // 节点值比较函数指针
unsigned long len; // 链表节点数量
} list;
压缩链表
下图是一个压缩链表的格式:
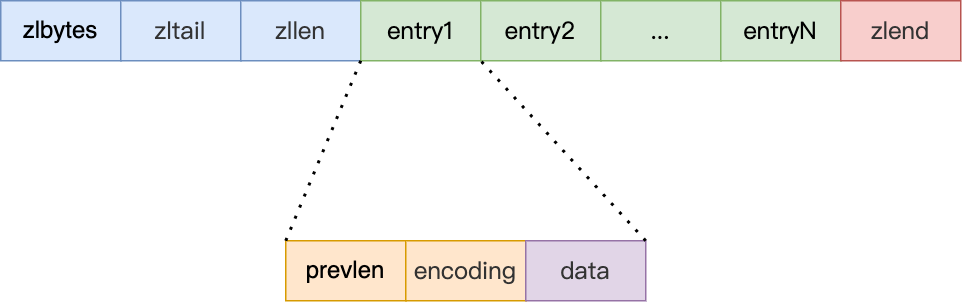
zlbytes:整个压缩链表占用字节数zltail:压缩列表尾部距离其实的字节数zllen:压缩链表中entry的节点数量zlend:压缩链表的结束标识符,为0xFFprevlen:前一个节点的长度,为了实现从后往前遍历,如果前面一个节点小于254字节,就用占一个字节,大于等于254字节,就占五个字节encoding:节点实际数据的类型和长度,类型主要有字符串和整数两种data:节点的实际数据,类型和长度由encoding决定
encoding编码如下所示:

压缩链表有一个严重缺点,就是连锁更新:
假如当前所有节点都只占用250~253字节,那么在最前面插入一个大于254字节的数据0,那么从当前第一个节点开始,都需要将prevlen从一个字节变成四个字节,所有的节点都需要改变,也有可能导致需要一个新的压缩链表才能存放的下。
哈希表
typedef struct dictht{
dictEntry **table; // 哈希表数组
unsigned long size; // 哈希表大小
unsigned long sizemask; // 哈希表大小掩码,用来计算索引值
unsigned long used; // 已有节点数量
} dictht;
typedef struct dictEntry{
void* key; // 键值对中的键
union {
void* val;
uint64_t u64;
int64_t s64;
double d;
} v ; // 键值对中的值
struct dictEntry* next; // 指向下一个哈希表节点,形成链表
}dictEntry;
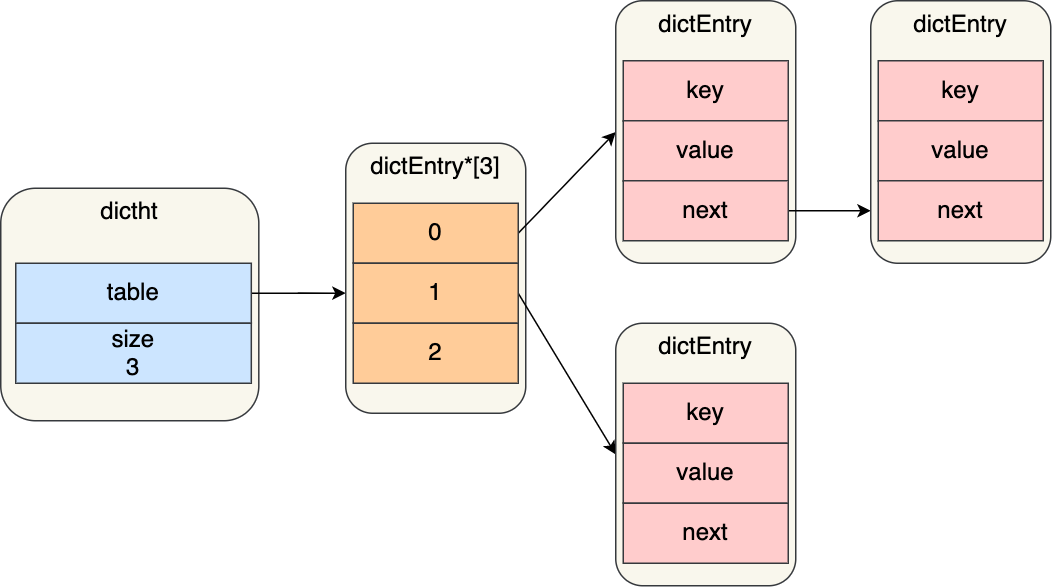
除了使用链式法来表示解决哈希冲突,然后还有一种方式叫做rehash,主要为了解决哈希表数据过多导致逐渐退化成链表的。
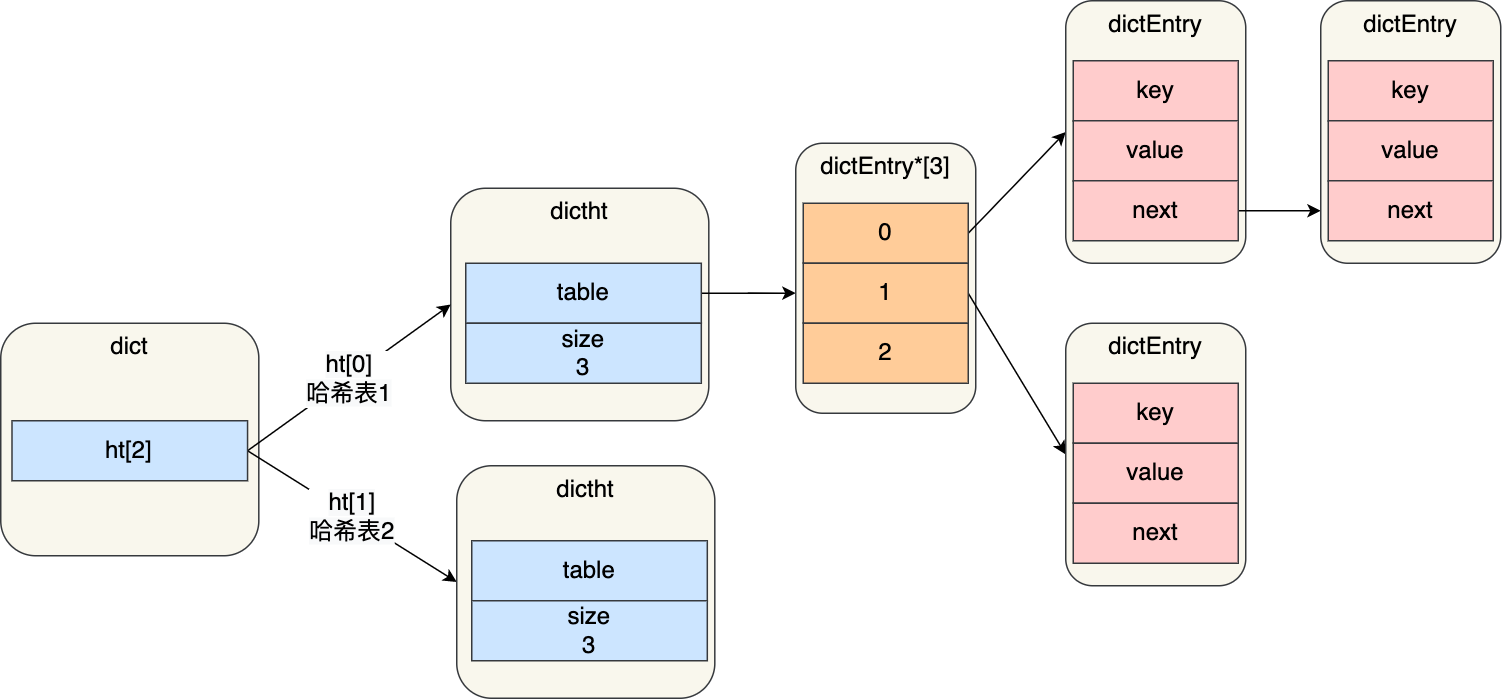
存在两个哈希表,一开始哈希表1分配空间,哈希表2不分配空间,
rehash过程如下:给哈希表2分配空间,一般为哈希表1的两倍
将哈希表1的数据迁移到哈希表2
释放哈希表1的空间,并将哈希表2设置成哈希表1
但是上述过程,如果哈希表数据过多,会造成严重阻塞,因此,使用了渐进式rehash:
- 给哈希表2分配空间
- 对哈希表元素进行新增、删除、查找和更新操作,除了执行操作,还会将设计的数据迁移到哈希表2上
- 随着越来越多请求,总会把哈希表1的数据迁移到哈希表2
- 如果在哈希表1中没找到数据,会在哈希表2上继续找
rehash触发条件:负载因子=哈希表保存的节点数量/哈希表大小
- 负载因子大于1:没有在执行
RDB快照或AOF重写,进行rehash - 负载因子大于等于5:直接执行
rehash
整数集合
typedef struct intset{
uint32_t encoding; // 编码方式
uint32_t length; // 元素长度
int8_t contents[]; // 实际存储地址
}intset;
实际存储的都是在int8_t数组中,但是却可以表示int16_t, int32_t等等,这是由于:
encoding==INTSET_ENC_INT16,那么contents就是一个int16_t数组,每个元素都是int16_tencoding==INTSET_ENC_INT32,那么contents就是一个int32_t数组,每个元素都是int32_tencoding==INTSET_ENC_INT64,那么contents就是一个int64_t数组,每个元素都是int64_t
在实际解析中,会根据encoding来变动指针,不仅仅是变动一个字节。除此之外,还可以升级,但是不能降级,升级指的是保存单个元素占用更高的字节。
会重新计算所需要的字节数,并逐步把数据迁移到后面。
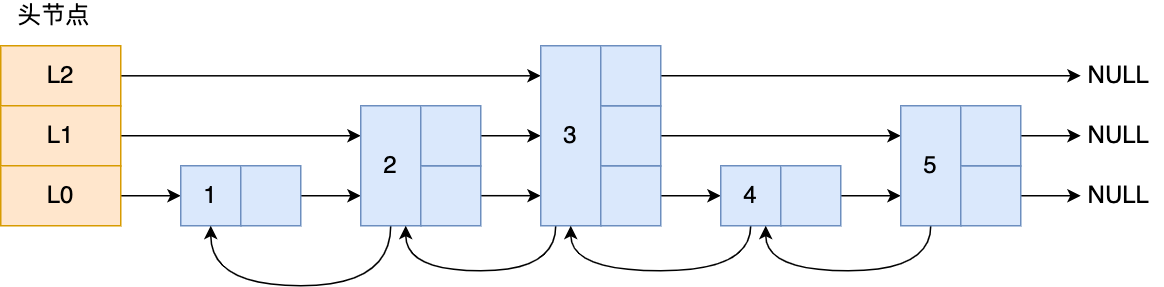
跳表
typedef struct zskiplistNode{
sds ele;
double score;
struct zskiplistNode* backward;
struct zskiplistLevel{
struct zskiplistNode* forward;
unsigned long span;
} level[];
}zskiplistNode;
typedef struct zskiplist{
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
}zskiplist;
- 查询过程:
- 从头节点的最高层开始,逐一遍历每一层,使用sds类型的元素和元素的权值判断
- 当前权重小于目标权重,跳表访问该层下一个节点
- 当前权重等于目标权重,并且当前节点的sds类型数据小于要查找数据时,访问该层下一个节点
- 如果2 3条件不满足,或下一个节点为空,访问当前节点下一层继续找,不需要返回头节点
跳表节点层数设置:
尽量要保证相邻两层节点数量比例是2:1,这样才可以降低查找复杂度为O(log N),跳表在创建的时候,会随机生成每个节点的层数
- 创建节点时,随机生成
[0-1]随机数 - 随机数小于
0.25,层数继续增加,然后继续生成随机数 - 随机数大于
0.25停止
最高层的话,只会有64层
使用跳表而不用平衡树:
- 内存会更少一点,平衡树每个节点需要2个指针,跳表每个节点需要
1/(1-p)个指针,redis中p=1/4,所以平均每个节点需要1.33个指针 - 对于范围查找,跳表的局部性比平衡树好,更好利用缓存
- 易于实现,调试等。插入删除比平衡树更有优势
quick list
这就是一个压缩链表+链表的组合
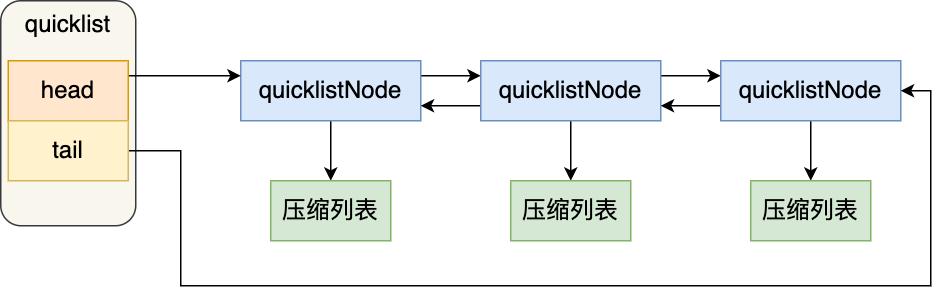
typedef struct quicklistNode{
struct quicklistNode* prev; // 前一个
struct quicklistNode* next; // 下一个
unsigned char* zl; // 压缩链表指针
unsigned int sz; // 压缩列表字节大小
unsigned int count; // 压缩列表元素个数
}quicklistNode;
typedef struct quicklist{
struct quicklistNode* head;
struct quicklistNode* tail;
unsigned long count; // 总元素个数
unsigned long len; // 节点个数
...
}quicklist;
listpack
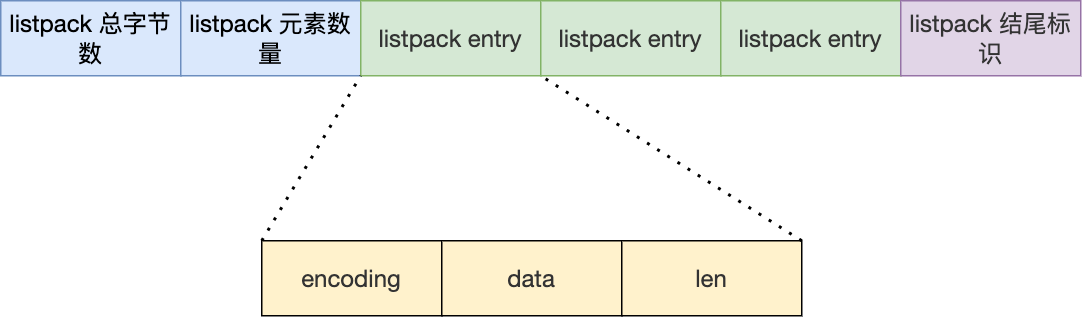
这是由len只表示当前节点的长度了,不用表示前一个节点的长度了,len=encoding+data长度