
这篇博客主要是写给自己看的,如果完全的初学者,建议看我的另外一篇博客。
1、requests模块的使用
response的用法
# ====== 1、基础知识 ======== # import requests url = "http://www.baidu.com" response = requests.get(url) print(respones.text) # 注意,text这个变量是默认解码过的,根据内容自动猜测的解码,str类数据 print(response.content.decode()) # content是没有解码的,bytes数据,默认用utf-8解码,也可以指定gbk解码,如decode('gbk') # 常见的解码方式:utf-8,gbk,gb2312,ascii,iso-8859-1 # 有些平台可能上述都不行,那就用bytes存储就好 print(responst.encoding) # 推测的遍码格式 # 当然可以先设置encoding response.encoding = "utf8" # 注意不是写成 utf-8 print(response.text) # 即可按照utf-8解码 # ====== 2、常见的对象参数和方法 ======== # # 响应的url print(response.url) # 状态码(一般来说,不要相信) print(response.status_code) # 响应对应的请求头 print(response.request.headers) # 响应头 print(response.headers) # 响应对应请求的cookie 返回cookieJar类型 print(response.request._cookies) # 响应的cookie print(response.cookies) # 自动将json字符串类型的响应内容转换成python对象 print(response.json())
关闭代理
proxies = {"http": None, "https": None} response = rq.get(url, headers=headers, verify=False, proxies=proxies) # 关闭代理,关闭ssl认证
2、浏览器中的操作合集(可切换成无痕有痕分别都操作,带入多种数值操作)
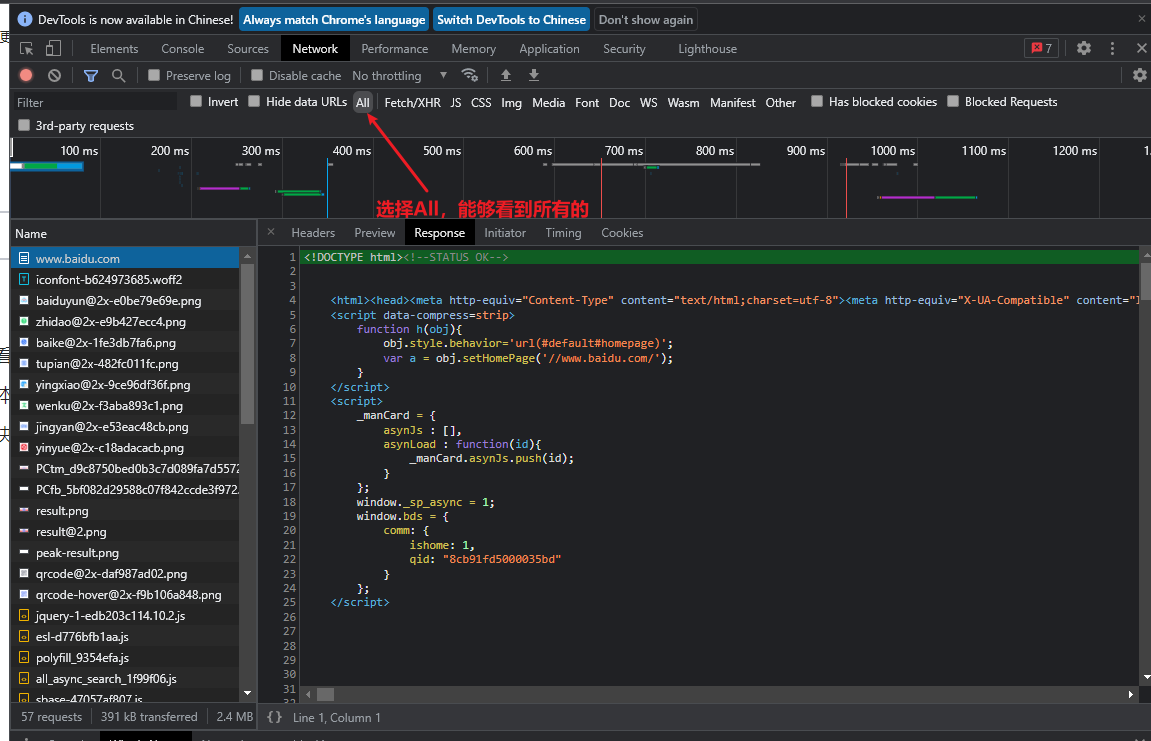
获取所有数据,勾选
All
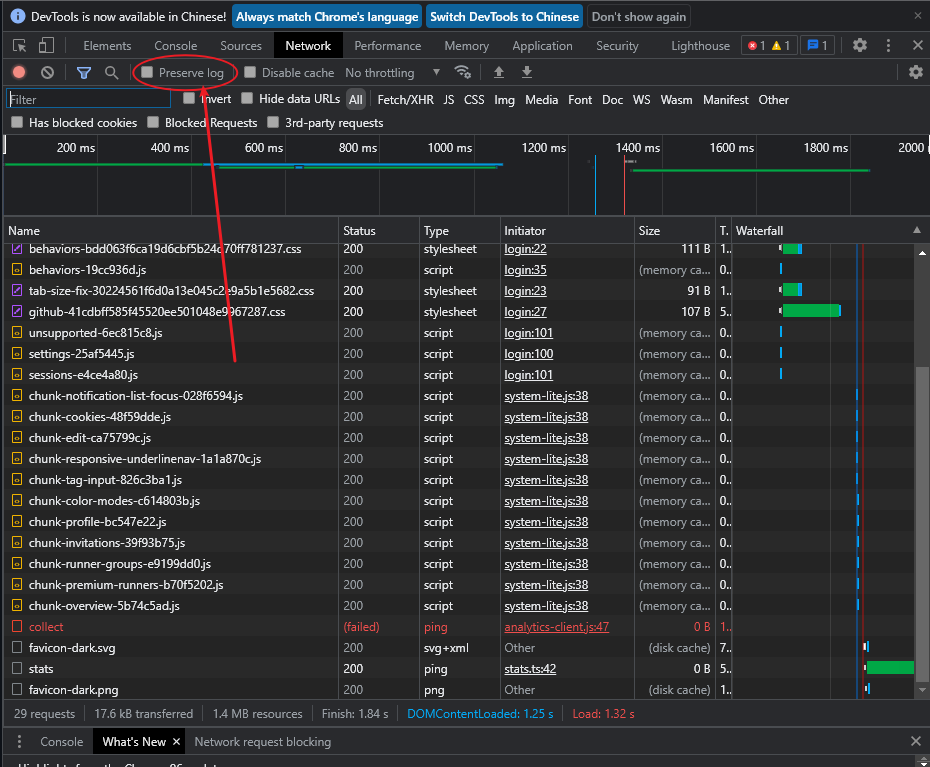
登录或者其他导致页面自动跳转,那么抓的包会刷新,勾选下面这个就不会刷新
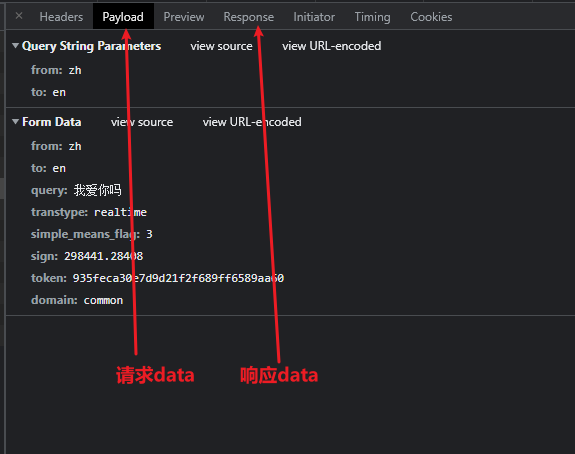
查看请求数据和响应数据
关于请求头的一些参数意义
Referer:这个是解释从哪个网站跳转的
User-Agent:包含了请求主机的信息,包括系统信息和浏览器信息,如果要伪装成浏览器,这个参数很重要
Cookie:这个分为请求cookie和响应cookie,分开使用
host:请求域名
Connection:是否保持连接,例如keep-alive,close
Upgrade-Insecure-Requests:升级为https关于响应头的一些参数意义 - 响应头一般是返回参数,主要看请求头
Set-Cookie:设置的cookie状态码:200表示成功,但是,一般不要关注状态码,因为其不可信
常见的单词意义
token:这个是一般为了保持的浏览器的连接性注意事项
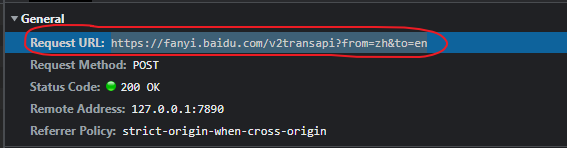
上面的
host是域名,不一定是请求url,请求url看下面图
其他帮助网站合集
免费代理站点
3、爬虫入门一
注意请求头中的一些参数
User-Agent:包含了很多参数,如浏览器数据,系统数据等headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36' # 最好不要加到这一行的值,因为会报错,不明白为什么 } headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)' } response1 = requests.get(url, headers=headers)发送带参数的请求
url直接带参数# http://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=python&fenlei=256&rsv_pq=8cb91fd5000035bd&rsv_t=368aR6DDwiiYX59pfDu4vQz2%2FajgsJuSG4IS8mBB5GeZwSo6Sn%2BjQuytYZM&rqlang=cn&rsv_enter=1&rsv_dl=tb&rsv_sug3=9&rsv_sug1=7&rsv_sug7=101&rsv_sug2=0&rsv_btype=i&prefixsug=python&rsp=5&inputT=2667&rsv_sug4=6046 # 如上面这个连接,可以尝试删掉一下不要的参数,最终得到下面这个 # http://www.baidu.com/s?wd=python # 这个才是关键,然后进行get请求 url = 'http://www.baidu.com/s?wd=python' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)' } ## 注意,get请求不要使用https response = requests.get(url, headers=headers)
- 使用
params携带参数字典url = 'http://www.baidu.com/s?' # 注意这里需要加上s?,这个是百度的特性 data = { 'wd': 'python' } heads = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)'} response = requests.get(url, params=data, headers=heads)携带
cookie信息,cookie一般有时效性,过段时间需要重新获取
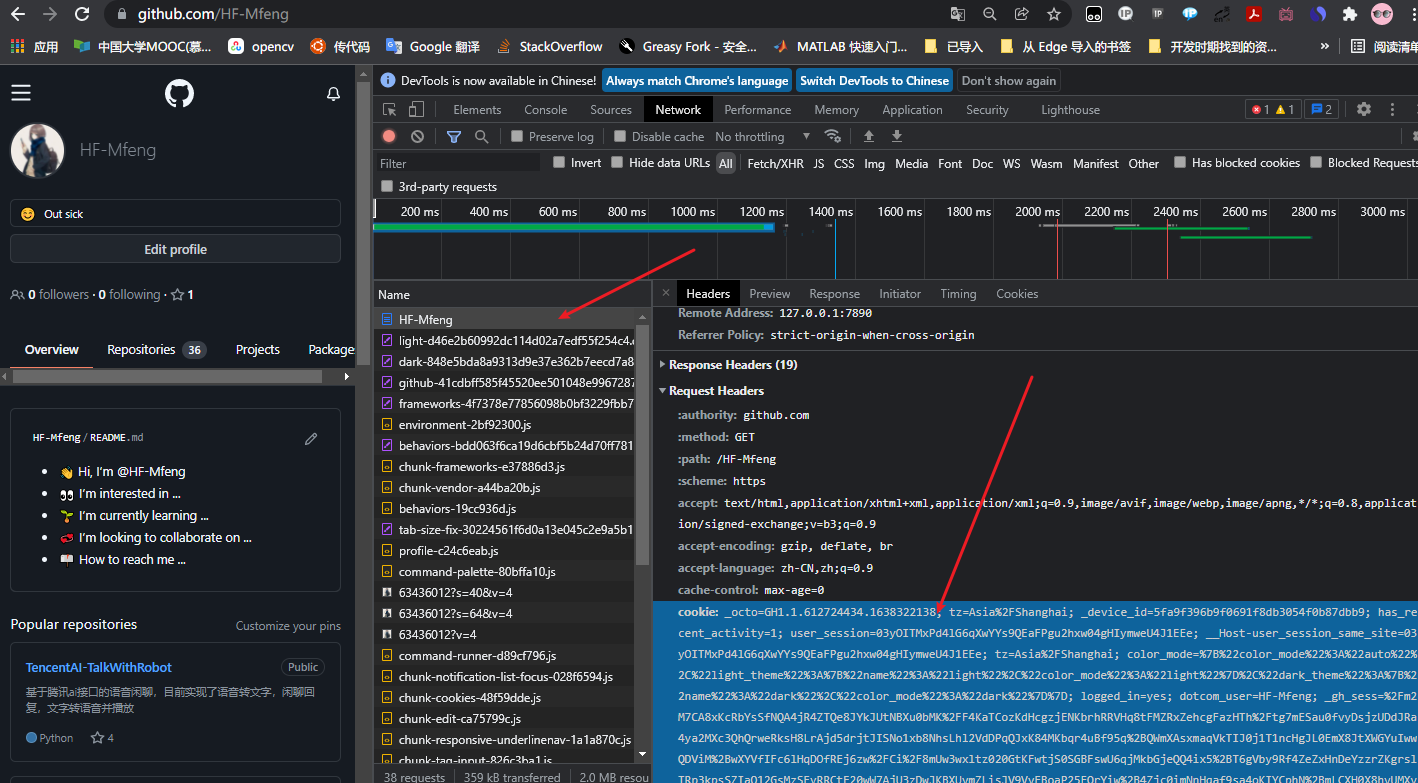
- 以
github为列见下列图片,浏览器抓包
- 在
headers携带headers={ 'cookie': 'xxxx', 'User-Agent': 'xxxx' }
- 使用
cookie参数来保持# 构建cookie字典 # 需要先切割键值对 # 如下列cookie cookies = '_octo=GH1.1.612724434.1638322138; tz=Asia/Shanghai; _device_id=5fa9f396b9f0691f8db3054f0b87dbb9; has_recent_activity=1; user_session=03yOITMxPd4lG6qXwYYs9QEaFPgu2hxw04gHIymweU4J1EEe; __Host-user_session_same_site=03yOITMxPd4lG6qXwYYs9QEaFPgu2hxw04gHIymweU4J1EEe; tz=Asia/Shanghai; color_mode={"color_mode":"auto","light_theme":{"name":"light","color_mode":"light"},"dark_theme":{"name":"dark","color_mode":"dark"}}; logged_in=yes; dotcom_user=HF-Mfeng; _gh_sess=Bvk3bQRV+XfUQlh+l8Mu2MKWcl7O+LH3nLtnVSWOFvzAo50NycqAlQFAYbNMdXfpVAxSU08+65qeCVG2+wX97z/sjsdsI2grX7uXpIWvFpAi/pOBPyt4dXjNRT5n2o2VTvCgIP2mWQEXTg7HVjs3v16QCj/eUFbd460btIb6J1NG/DY1wW7jx8/VAS2vkFVZ7uTkoljKQdcs8K7oAndejxw7f3fdBKCybeghEIqu71SonF5C774enN5nq2zNtSILtA7lEA+s72ekWtLrFkzRpAoi+rzQLR2naFzIXCuFbbCdsLj7tNRAF8Uj0vyRn29LdqxbjMsssMmiiBVi81x3Vf7awZRHhjp2jzMINq+J3grHfOyjgwer1XRXkUW4RaIayrC60XOl/NG5tOPUmPCHqDkHhAyFx3TRVxhz84a+oxBSW9PJK4ebYu2sZrA3nCOdRkPDvEoMehgxhZuOz07e8usCuKc//p/tozi/WI+CuPWjYamF3Hyv1uYt4C1sKjZbhNzH3sjd+9hD5DP33IROZWlvCM4W2PWmq6RWyC5B1Dyk8pAq89W87dsdm5W2eyMo/xNLdwZi+o8cXkJROi8W/XQa6NwRWlh9yON+xl3L9Txtesvi3mlB7b1L+ic/XR4f7Wh8C59yeyY67lijumG/qfX0F8w3H76BPnlmbH9oxL4qRkWwVSflal4LjRhgOaoiCZzs1r6oellyNV6pPilm7QRbP7KEnq+R+PusPQsDBWn4Gej/vbQ2P9cwqW9EQr+VhsV6MHUvhuGAY8MRB5eBKtxrhqXZMiLYak0Pk82cl9oesvU5tqp3xNo2VNHWXt5uM6YLQTggbG+spmuxqnbHt481AoMUNnRcN6WomLZ4vS4pYXO5NLa58uk9slgT/3iwPEWsy7HuK5FLYqcMvPTGNeO+nYs=--c91BUqTy9ZXXOfRr--YhanrwguBRPMP5S/I3ig0A==' cookies = cookies.splie("; ") cookies_ = {} for cookie in cookies: cookies_[cookie.split('=')[0]] = cookie.splie('=')[-1] # 其中有许多的等号,如_octo=GH1.1.612724434.1638322138,就是一个键值对 respose = requests.get(url,headers=headers,cookies=cookies_)
cookieJar对象转换成cookie字典,一般用不到# 什么是cookieJar对象呢,如下 requests.get(url).cookie # 这个就是cookieJar对象 dict_cookies = requests.utils.dict_from_cookiejar(response.cookies) # cookiejar转换成字典 jar_cookies = requests.utils.cookiesjar_from_dict(dict_cookies) # 重新转化成cookiejar
timeout的用法
- 设置一下
wresponse = requests.get(url, timeout=3) # 设为3s,一般设个十秒左右就好代理
Proxy代理分为正向代理和反向代理
代理还分为透明代理、匿名代理、高匿代理
- 透明代理
REMOTE_ADDR = Proxy IP HTTP_VIA = Proxy IP HTTP_X_FORWARDED_FOR = Your IP
- 匿名代理
REMOTE_ADDR = Proxy IP HTTP_VIA = Proxy IP HTTP_X_FORWARDED_FOR = Proxy IP
- 高匿代理
REMOTE_ADDR = Proxy IP HTTP_VIA = not determined HTTP_X_FORWARDED_FOR = not determined代理还可分为,
http、https、socks
http:目标url为http协议https:目标url为https协议socks:只传递数据包,不在乎什么应用协议,耗时少用法
proxies = { 'http': 'http://127.0.0.1:7890', 'https': 'http://127.0.0.1:7890' } response = requests.get(url, proxies=proxies)
- 并且代理站点可能会给你添加一下信息,使得你更像一个浏览器
- 代理也有可能截获你的数据,所以这个也要注意
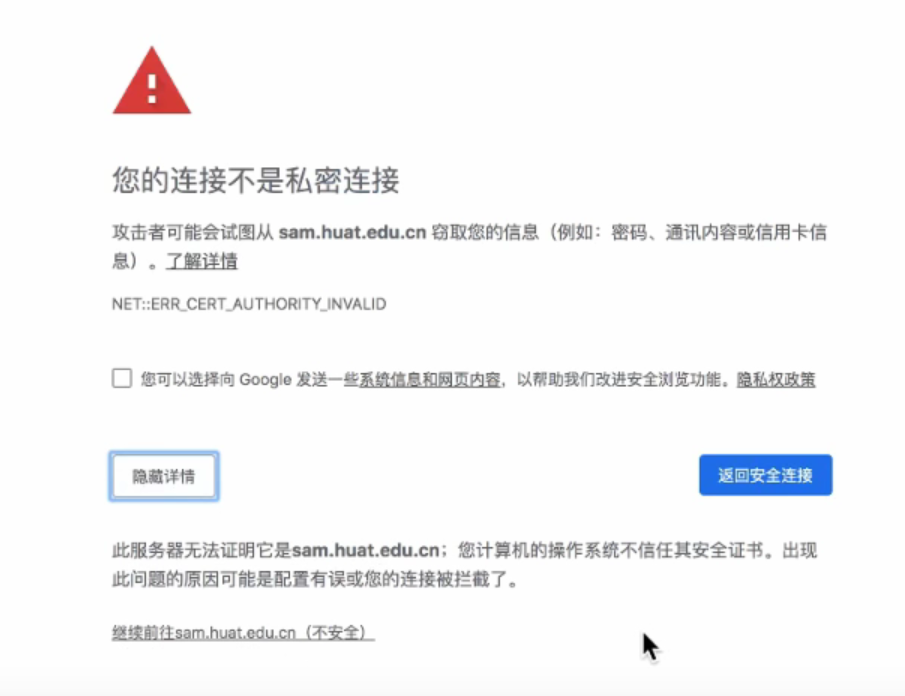
verify忽略CA证书很多情况如下图所示
爬虫过程遇到下列情况
requests.exceptions.SSLError: HTTPSConnection.....设置为
False即可# 默认是True,设置为False # 运行过程会报警告的,但是 don't worry it 爬虫还是可以爬取内容的 response = requests.get(url, verify=False)
post请求
post用途
- 一般有账号密码,都会使用
post请求,因为get请求是在url中的明文- 大文件以及多数据,都是使用
postweb工程师会认为post比get请求更加安全简单实现
respose = requests.post(url, data) # data是一个字典找
data的步骤寻找固定值:一般来说浏览器抓抓包就知道了
- 寻找输入值:也一般来说浏览器抓抓包就知道了
- 寻找预设值 - 静态文件:一般来说,需要从
html文件中搜索,可以尝试,这个是反爬的- 寻找预设值 - 发请求:需要对指定地址发送请求
- 寻找动态生成值:一般是客户端生成的,反爬的重点,一般采用
Javascript生成
data反爬套路
- 模仿其他浏览器发送,如手机什么的,因为很多浏览器都是不一样的反爬,找个弱的
- 注意时间戳什么的
- 注意里面的
JS文件- 有些可能是随机值
- 从
html提取,可以试试无痕浏览器
requess.session状态保持
- 自动保持
cookie,一般多次请求(如登录之后再操作的),使用方法session = requests.session() session.headers = { } session.data = { } response = session.get(url) response = session.post(url) # 如下用法 s = rq.session() s.trust_env s.verify s.headers s.proxies s.cookies s.get(url, data=data) s.post(url, data=data)
正则表达式,这个也是重点
首先如何使用正则表达式
response = requests.get(url) restr = response.content.decode() # 转成utf-8或者gbk # 正则提取 import re # 导入正则模块 str_tmp = "<link href=\"https://stacdn.proginn.com/plugin/swiper/swiper.min.css?version=4.30.2\" rel=\"stylesheet\" type=\"text/css\">" # 临时字符串,不用写到代码里 # 假如想要获取上面中的href,那么这样写正则表达式 # 正则 restr = '<link href=\"(.*?)\" rel=\"stylesheet\" type=\"text/css\">' # 这个是以非贪婪模式匹配多个字符 # 然后匹配一下全文,看看是否获取了对应的 dst_list = re.findall(restr, str_tmp) # 打印一下看看就知道了
额外补充知识
form表单
- 以
github为例- 一般来说,
form表单上面会有很多消息可挖掘,如下图所示
- 其中,
action指的是提交给的路径method是提交方法token这个一般用来表示保持的意思,同行的value表示token的值- 而下面这个
name,就是输入标签将里面的值提交给什么了,这里是提交给login往往需要多次抓包,多次比较才行,找出差异
- 如在无痕串口进行多次退出和登录
- 主要是为了找出
post的变值(不包括输入值,除非输入值不是明文传输)注意多次爬虫,需要注意页面的跳转
- 比如登录的时候,一般会跳转的

结束语
技术永远是好东西,只是拿来做什么